正则表达式与三剑客
简介
正则表达式主要是用来过滤文本中特定的字符串的,比如过滤身份证号码,过滤手机号码等,很多编程语言中都会用到正则表达式,它们之间的规则大同小异,核心语法是一样的,在Linux中主要是给grep、sed、awk用的,下面是一个非常常用的正则语法,不显示文本中的空行和注释
[root@node1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.112 node1
192.168.1.113 node2
192.168.1.114 node3
#192.168.1.118 node6
[root@node1 ~]# cat /etc/hosts | egrep "^#|^$"
#192.168.1.118 node6
[root@node1 ~]# cat /etc/hosts | egrep -v "^#|^$"
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.112 node1
192.168.1.113 node2
192.168.1.114 node3
正则表达式是一行一行来工作的
正则表达式规则合集
基本正则
^ 匹配开头
$ 匹配结尾
^$ 匹配空行 (这一行不包含 空格 TAB 什么都没有)
. 匹配任意1个字符
* 匹配前1个字符 0次或多次 [0, ∞)
.* 匹配所有内容,无论这一行是什么均匹配上
[azx] [256] 匹配字符 a OR z OR x
[a-d] [0-9] 匹配字符 a OR b OR c OR d
[^a-d] [0-9] 上面内容的取反
\ 转义字符,撬棍,取消某个字符的特殊含义 (此时可以直接使用fgrep)
扩展正则
+ 匹配前1个字符1次或多次 (最少1次) [1, ∞)
[0-9]+ [a-c]+ 懂!
? 匹配前1个字符0次或多次 [0, 1]
| 表示或者 OR
() 分组过滤,被括号括起来表示一个整体,也可用作 \1 \2 .. 后向引用
\n 引用前面括号里的内容,例如,(aa)\1,匹配aaaa
a{n} 匹配前1个字符 n次 下面的n,m都是正整数
a{n,} [n, ∞) 匹配前1个字符 最少n次
a{n,m} [n, m] 匹配前1个字符 最少n次,最多m次
a{,m} [0, m] 匹配前1个字符 最少m次
可以在 man grep 里看到正则表达式的简要帮助
直接grep支持基本则,egrep OR grep -E支持基本正则和扩展正则
常见实践场景
正则表达式的基本语法规则,不是太多,但组合起来有很大灵活运用的空间,另外学习Linux正则表达式,建议至少要对grep命令比较熟练,这个命令用来测试正则表达式非常方便,自带红色高亮可以直观看到效果
对于比较复杂的正则表达式规则,要想准确写出来,除了语法之外,更重要的是首先要弄清楚想要匹配字符串的规律,比如匹配手机号:
规则1 一共11位 (这个也不是那么绝对,个别地区还有12位的,这里还不考虑外国手机号的情况)
规则2 开头3位是比较固定的 (这又需要个手机开头3位情组合大全什么的)
再比如匹配IP地址,一想就觉得规则很多,不用说正则,用汉字把规则详细打出来,就需要一凡功夫,不过类似这种复杂的正则表达式,最快的解决方案是直接百度,平常每人会去记这个
下面尽量列举一些,运维工作中常见的,基本不需要百度,随手拿来就能用的正则使用场景
场景1:不想看到文本中的注释和空行
cat /etc/hosts | egrep -v "^$|^#"
场景2:找出3306端口或1521端口
netstat -lntup | egrep "3306|1521"
场景3:把毫秒转换成微秒
echo "1583419889856" | egrep "[0-9]{10}"
括号使用-后向引用
括号的在正则表达式中的使用提供了一种类似于子匹配模式(subpattern),括号可以提供3个功能:重复整个字符串而不是单个,后向引用,使正则表达式可读性更高。示例如下:
'(red|blue) plate' # 匹配red plate 或者 blue plate
'red|blue plate' # 匹配red 或者 blue plate
'(150){3}' # 匹配 150150150
'150{3}' # 匹配 15000
实践举例
现有一文件,内容如下:
[root@as4k /as4k]# cat dog.txt
The red dog fetches the green ball.
The green dog fetches the blue ball.
The blue dog fetches the blue ball.
可以看到只有第3行,狗的颜色和球的颜色都是蓝色,我们的目标就是匹配相同颜色的那一行。如果我们这样写:
egrep '(red|green|blue).*(red|green|blue)' dog.txt
得到的效果如下:

可以看到,结果不是我们想要的。此时如果我们使用后向引用,也就是这样写:
egrep '(red|green|blue).*\1' dog.txt
得到的效果如下:

可以看到,正是我们需要的效果。
正则的执行顺序
'pat{2}ern|red' # 匹配 pattern 或者 red
先执行{2},后执行连接字符串操作,最后执行或操作。
可以通过括号改变执行顺序。
POSIX Character Classes

排除文件的的空行,空格行
egrep -v '^[[:blank:]]*$' lidao.txt
grep
grep命令相信大家都不陌生,非常常用,就像在浏览器里经常需要CTRL+F搜东西一样
egrep means grep -E fgrep means grep -F ,egrep是支持扩展正则表达式,fgrep是搜索固定的字符串,取消特殊符号的正则功能,并且fgrep拥有更高的性能
用 grep --help ,直接查看最核心的帮助内容
[root@node1 ~]# grep --help
Usage: grep [OPTION]... PATTERN [FILE]...
Search for PATTERN in each FILE or standard input.
PATTERN is, by default, a basic regular expression (BRE).
....
grep --help 核心技能概览
man grep 中端操作
info grep 高端操作
列举几个我平常工作中常用的参数
-i, --ignore-case ignore case distinctions
-v, --invert-match select non-matching lines
-n, --line-number print line number with output lines
-o, --only-matching show only the part of a line matching PATTERN 由于三剑客的规则都是按照行来的,会把符合匹配规则的一行都打印出来,但是有时候我们不想看到整行的内容,只需要"红色高亮"部分
-R, --dereference-recursive 递归遍历,在某个目录及子目录里找东西
-c, --count print only a count of matching lines per FILE 一般该功能更多的是用wc -l来实现
--colour=auto 上色
使用实践
grep -i 'hello.*world' menu.h main.c
grep -l 'main' *.c 加上-l参数,只显示文件名,其实不加也会显示文件名
grep -r 'hello' /home/gigi -r 与 -R 功能一样
grep -w 'hello' *
grep 'hello\>' *
grep 'paul' /etc/motd | grep 'franc,ois'
To match empty lines, use the pattern `^$'. To match blank lines,
use the pattern `^[[:blank:]]*$'.
表示并且的查找
cat filename | grep regexp | grep regexp2
持续监控系统日志,以查看是否有警告
tail -f /var/log/messages | grep WARNING
通配符与正则表达式的区别
通配符是系统命令使用,一般用来匹配文件名或者什么的用在系统命令中。 正则表达式是操作字符串,以行为单位来匹配字符串使用的
sed
sed OPTIONS... [SCRIPT] [INPUTFILE...]
sed --help
-n, --quiet, --silent suppress automatic printing of pattern space
-i[SUFFIX], --in-place[=SUFFIX] edit files in place (makes backup if SUFFIX supplied)
-r, --regexp-extended use extended regular expressions in the script.
sed --version
完整的sed在线文档
https://www.gnu.org/software/sed/manual/sed.html
sed 's/hello/world/' input.txt > output.txt 这是sed最常用的功能,替换文本里的内容
sed -i 's/hello/world/' file.txt
sed -i 's/hello/world/g' file.txt
sed -i "s/#UsePrivilegeSeparation.*/UsePrivilegeSeparation no/g" /etc/ssh/sshd_config
sed -i "s/UsePAM.*/UsePAM no/g" /etc/ssh/sshd_config
用sed修改/test/abc.txt的23行test为root
sed -i '23 s#test#root#g' /test/abc.txt
sed -n '45p' file.txt
sed -n '45,$p' file.txt
sed '30,35d' input.txt > output.txt
sed '2d' person.txt
sed '1d' person.txt
[addr]X[options]
sed '/^foo/d ; s/hello/world/' input.txt > output.txt
sed '2a CSO' person.txt
sed '2i CSO' person.txt
sed '2a CSO\nCXX' person.txt
删除空行
sed -r '/^$|^#/d' /etc/inittab
The s Command
The syntax of the s command is s/regexp/replacement/flags
去掉不想看到的开头第1行内容
free -h | sed 1d
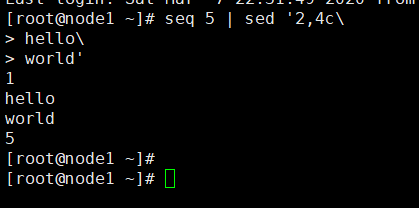
[root@node1 ~]# seq 5 | sed '2,4c\
> hello\
> world'
1
hello
world
5
快速的更改配置文件的内容
[root@node1 ~]# cat sshd_config | grep ForceCommand
# ForceCommand cvs server
[root@node1 ~]# cat sshd_config | sed '/ForceCommand/c hello-world-666'
把含有 "ForceCommand" 这一行,替换为hello-world-666
[root@node1 ~]# cat sshd_config | sed '/ForceCommand/c hello-world-666' > sshd_config.bak
[root@node1 ~]# diff sshd_config sshd_config.bak
139c139
< # ForceCommand cvs server
---
> hello-world-666
[root@node1 ~]# vimdiff sshd_config sshd_config.bak
批量替换整个目录里的文件
sed -i 's#http://md-images\.as4k\.top:8001#https://gitee\.com/as4k/xdocs/raw/master/image#g' `grep -Rl "md-images" /xdata/xdocs/content`
find /data/xdocs/content -type f -name "*.md" -exec sed -i 's#(http://md-images#(https://md-images#g' {} \;
后向引用
[root@app1 tmp]# cat tmp.txt
connector-consumer-dp-sqlserver-sink-connector-dptask_1051_4-0-67f366c9-bab1-4ced-b24b-8e48cf19a1ee
connector-consumer-dp-sqlserver-sink-connector-dptask_1051_4-3-e5de66ba-59ef-4ba6-8010-1956bcc92a3d
connector-consumer-dp-sqlserver-sink-connector-dptask_1051_4-2-25f24418-4980-44f9-8a3c-6ded3d944a21
connector-consumer-dp-sqlserver-sink-connector-dptask_1051_4-1-058abfe6-6872-4173-a930-1574e96dbd17
[root@app1 tmp]# cat tmp.txt | sed -r 's#(dptask_[0-9]+_[0-9]+-[0-9]+)-#\1 #g'
connector-consumer-dp-sqlserver-sink-connector-dptask_1051_4-0 67f366c9-bab1-4ced-b24b-8e48cf19a1ee
connector-consumer-dp-sqlserver-sink-connector-dptask_1051_4-3 e5de66ba-59ef-4ba6-8010-1956bcc92a3d
connector-consumer-dp-sqlserver-sink-connector-dptask_1051_4-2 25f24418-4980-44f9-8a3c-6ded3d944a21
connector-consumer-dp-sqlserver-sink-connector-dptask_1051_4-1 058abfe6-6872-4173-a930-1574e96dbd17
空格替换为TAB键
column -t tmp.txt | sed -r 's#[ ]+#-#g' | sed 's#-#\t#g'
awk
[root@node1 ~]# awk --help
Usage: awk [POSIX or GNU style options] [--] 'program' file ...
POSIX options: GNU long options: (standard)
-f progfile --file=progfile
-F fs --field-separator=fs
-v var=val --assign=var=val
-V --version
Examples:
gawk '{ sum += $1 }; END { print sum }' file
gawk -F: '{ print $1 }' /etc/passwd
$0 当前整行记录
$n 第n列,n是正整数
NF 总列数
$(NF-n)
NR 已经读出的记录数,行号,从1开始
awk -F 'GET|HTTP' '{print $2}' access.log
awk -F 'GET|HTTP' '{print $2,$3}' access.log
awk -F 'GET|HTTP' '{print $2" "$3}' access.log
awk 'NR==20,NR==30' file.txt 相当于 sed -n '1,6p' file.txt
awk 'NR>1&&NR<4' file.txt
截取 X ~ 最后一行
enum=$(wc -l file.txt)
awk 'NR==740469,NR==$enum' file.txt
利用awk打出时间,查看网络延时
#ping baidu.com | awk '{print $0 " " strftime("%Y-%m-%d %H:%M:%S", systime())}'
统计某个相关进程CPU使用累加和
ps aux | fgrep "php-fpm: pool api.xxxx.cn" | awk '{ sum += $3 }; END { print sum }'
https://likegeeks.com/awk-command/
https://gregable.com/2010/09/why-you-should-know-just-little-awk.html
https://www.gnu.org/software/gawk/
The GNU Awk User’s Guide 超全在线文档
https://www.gnu.org/software/gawk/manual/gawk.html
习题
文件ip.txt中包含很多IP地址(以及其它非IP数据),请打印出满足A.B.C.D 其中A=172 C=130 D<=100 条件的所有IP(请用AWK实现)
172.16.161.57
172.16.130.157
172.17.153.16
172.23.28.57
172.16.130.57
解答:
awk -F . '{if (($1==172 && $3==130 && $4<101)) print $0}' ip.txt
awk -F . '$1==172 && $3==130 && $4<101 {print $0}' ip.txt
综合应用
输出文本偶数行
sed -n '1~2 p' employee.txt
seq 11 | awk 'NR%2==0{print $0}'
取指定行号
sed -n '20,30p' oldboy.txt
awk 'NR==20,NR==30' oldboy.txt
修改网卡配置
已知网卡配置文件内容如下,要求修改IP地址为10.0.0.30
/etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
NM_CONTROLLED=yes
ONBOOT=yes
IPADDR=10.0.0.201
NETMASK=255.255.225.0
GATEWAY=10.0.0.254
参考方案:
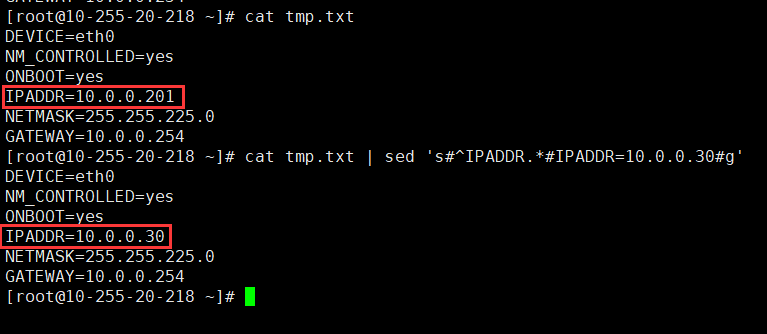
[root@10-255-20-218 ~]# cat tmp.txt
DEVICE=eth0
NM_CONTROLLED=yes
ONBOOT=yes
IPADDR=10.0.0.201
NETMASK=255.255.225.0
GATEWAY=10.0.0.254
[root@10-255-20-218 ~]# cat tmp.txt | sed 's#^IPADDR.*#IPADDR=10.0.0.30#g'
DEVICE=eth0
NM_CONTROLLED=yes
ONBOOT=yes
IPADDR=10.0.0.30
NETMASK=255.255.225.0
GATEWAY=10.0.0.254
过滤掉配置文件中的注释和空行
cp /etc/ssh/sshd_config{,.bak}
egrep -v "^$|^#" /etc/ssh/sshd_config
取身份证号码
[root@as4k /as4k]# cat id.txt
金 211324198705244720
万 500224197105168312
任 1231231231oldboy
任 3oldboy
任 lidao97303136098
任 alex2197303136098
任 350182197303oldgir
吕 211282199209113038
孔 150000198309176071
邹 371001197412221284
贺 130185200011215926
杜 362522198711278101
向 14052219961008852X
向 140522199610088522X
[root@as4k /as4k]# egrep '[0-9]{17}[0-9X]' id.txt
金 211324198705244720
万 500224197105168312
吕 211282199209113038
孔 150000198309176071
邹 371001197412221284
贺 130185200011215926
杜 362522198711278101
向 14052219961008852X
向 140522199610088522X
用户密码
格式为:以字母开头,长度在6-18之间。写出正则表达式。
^[a-zA-Z].{5,17}$