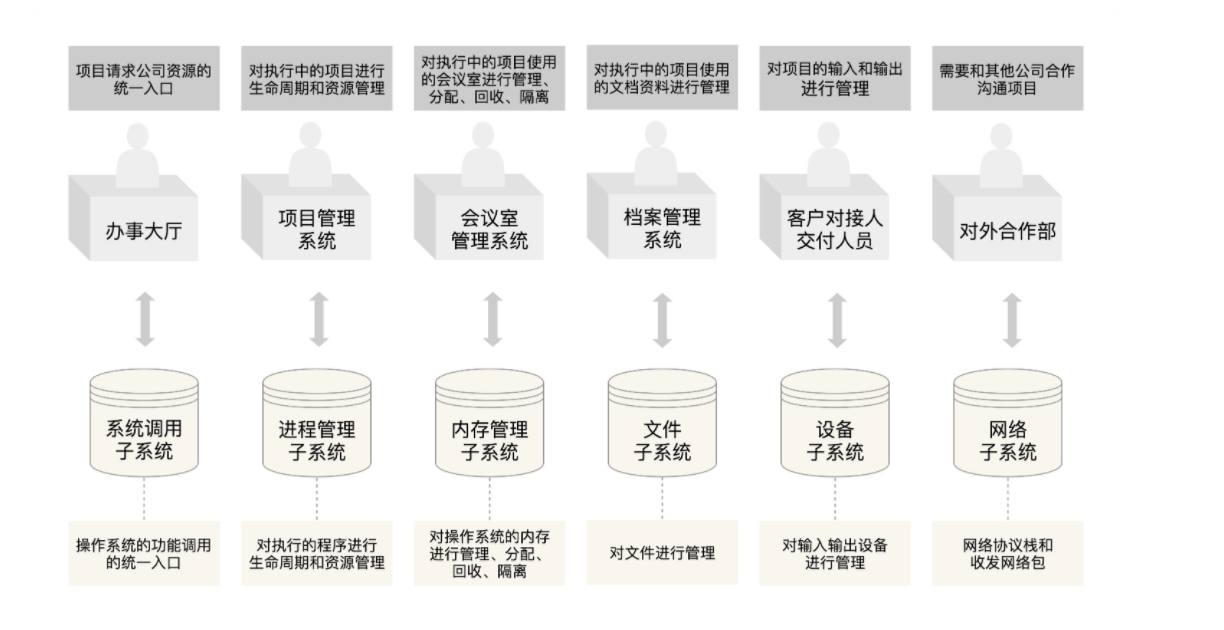
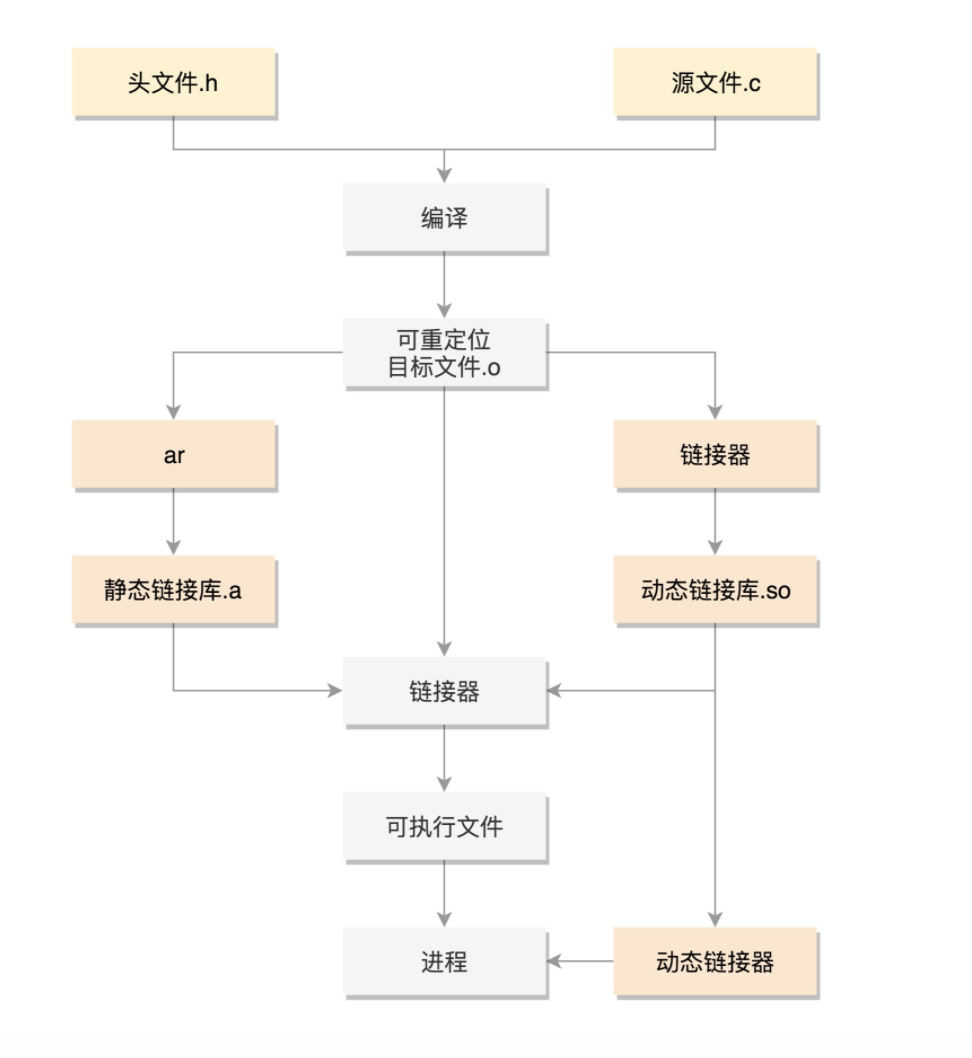
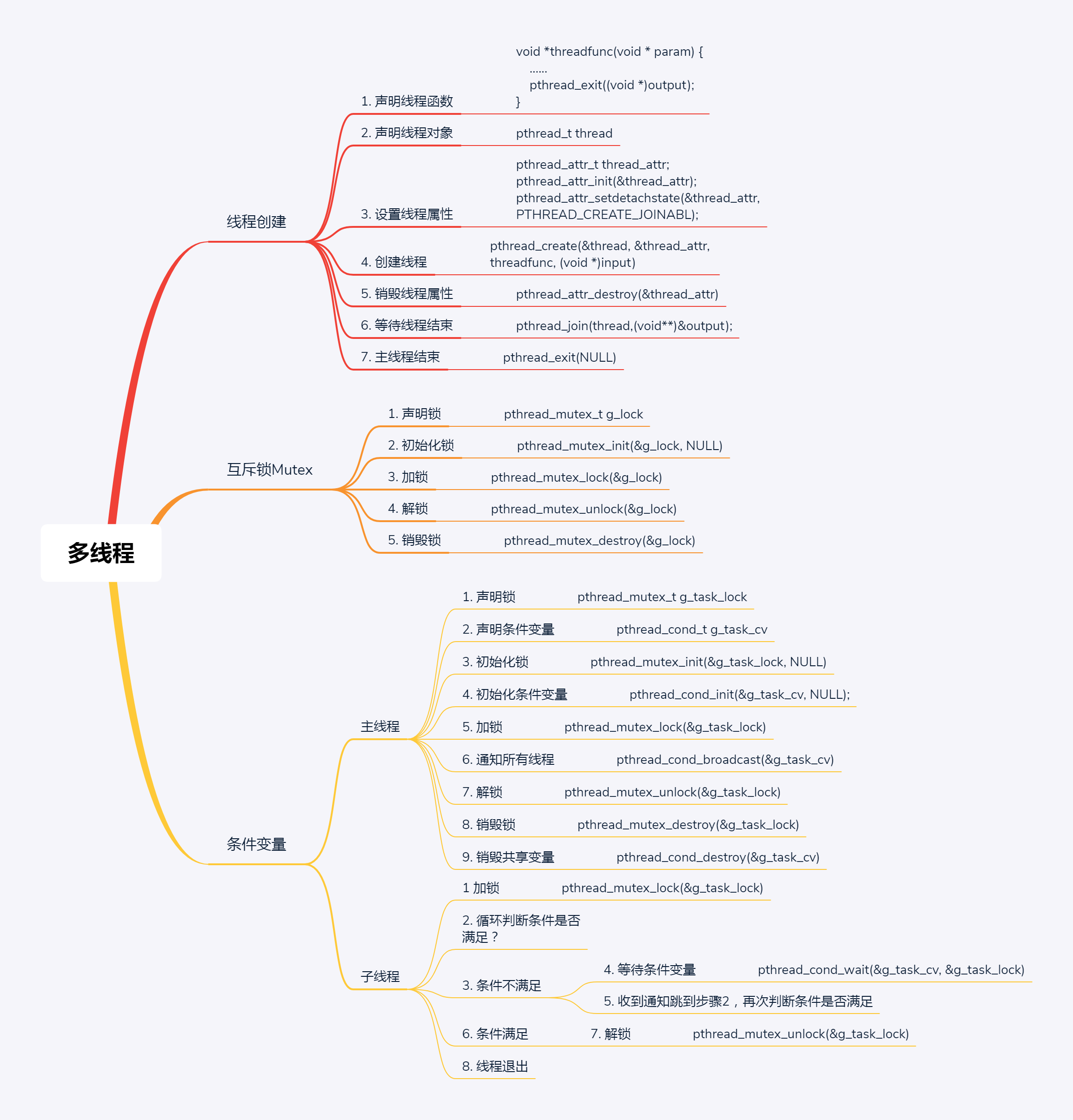
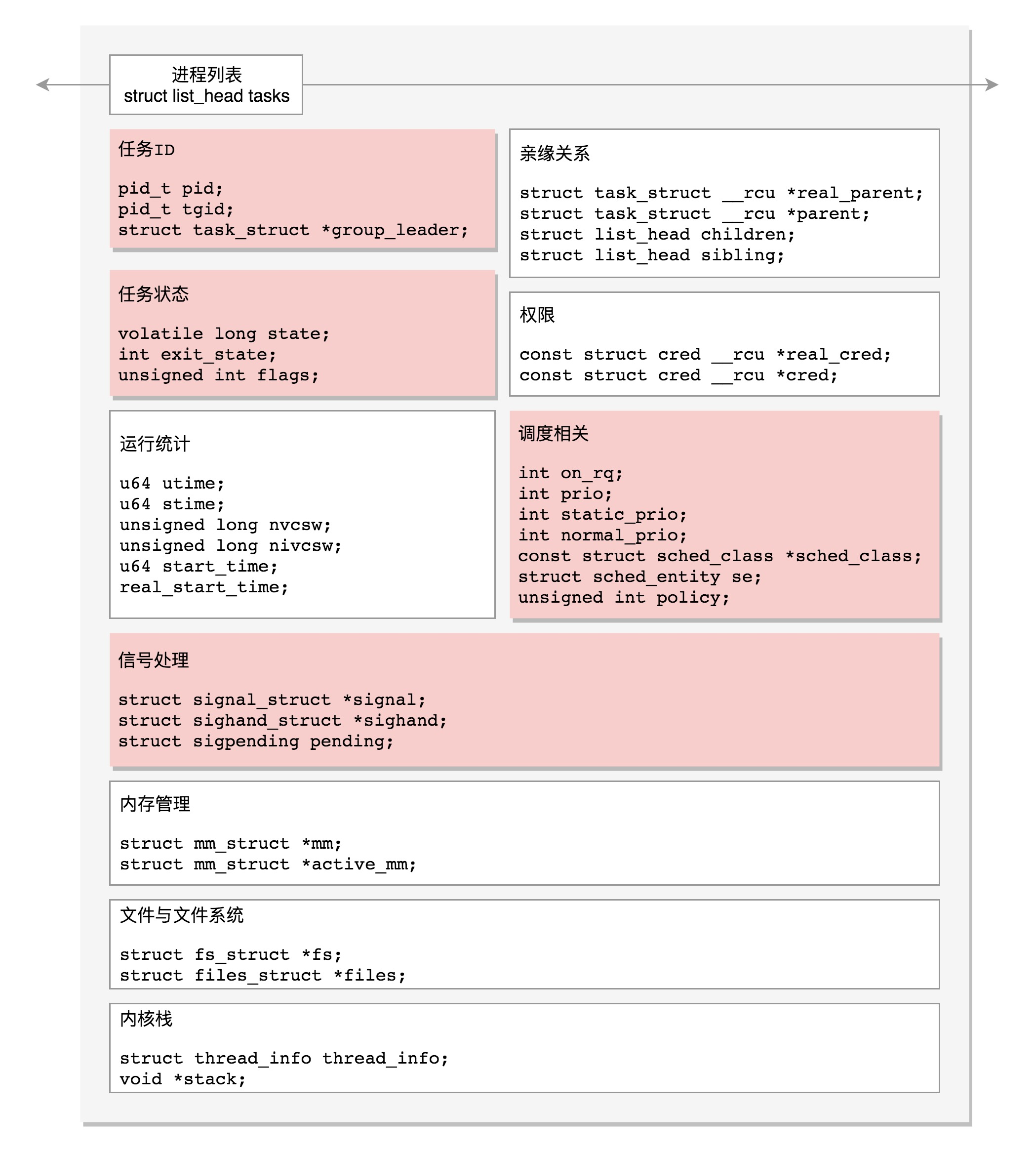
趣谈Linux操作系统
https://time.geekbang.org/column/intro/164
https://time.geekbang.org/column/article/160528
课程大纲

11张图 一览Linux操作系统全流程


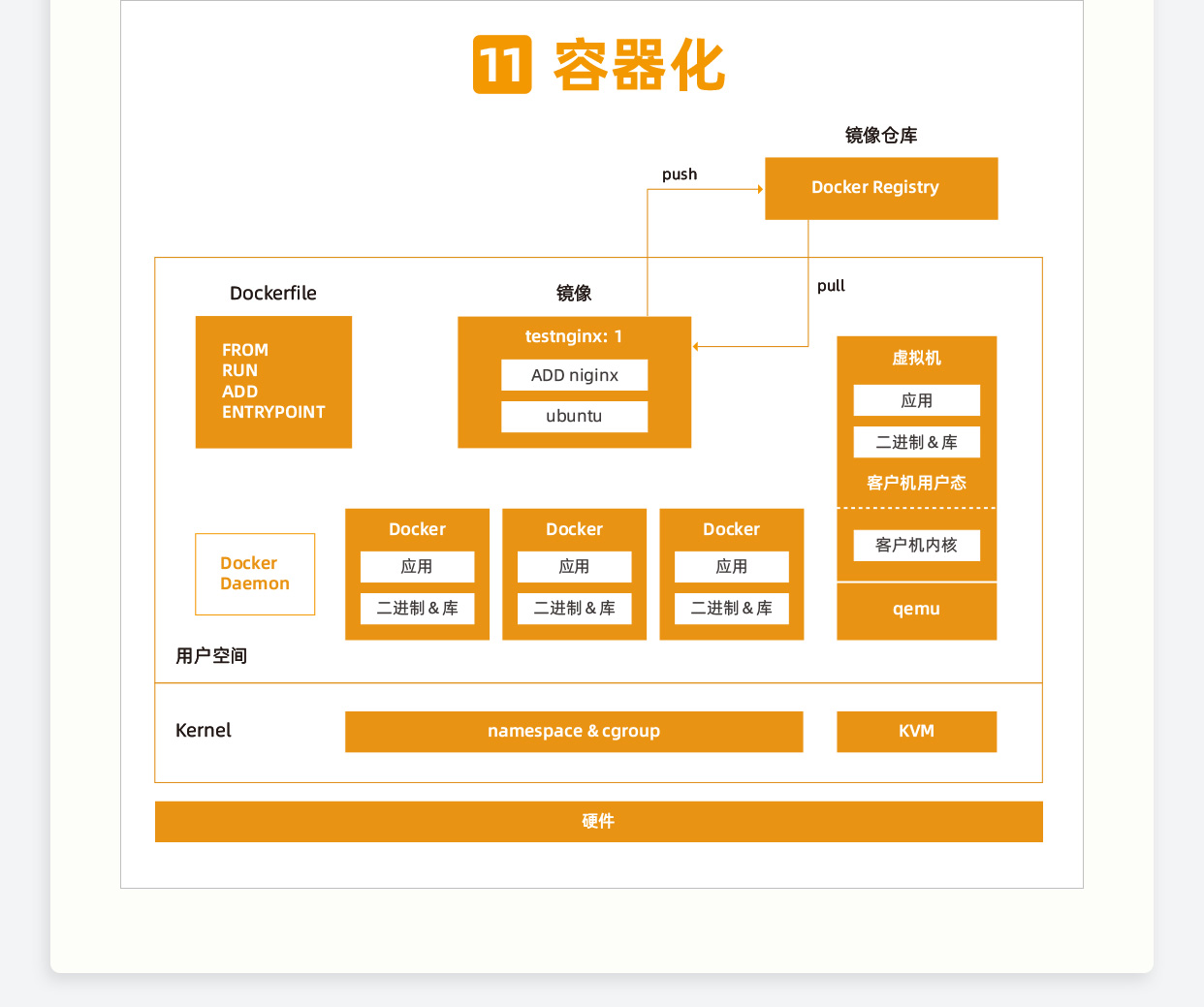
精华节选

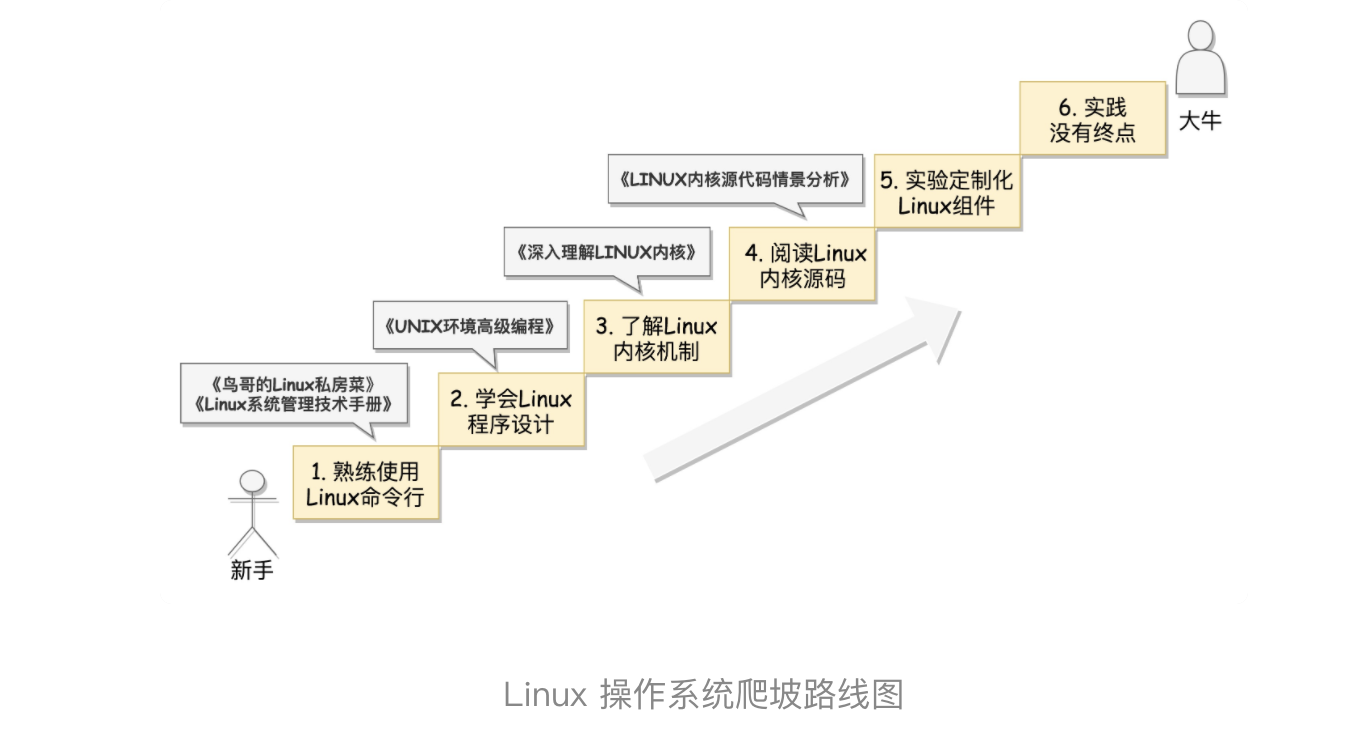
如果你想全面学习 Linux 命令,推荐你阅读《鸟哥的 Linux 私房菜》。如果想再深入一点,推荐你阅读《Linux 系统管理技术手册》。这本砖头厚的书,可以说是 Linux 运维手边必备。
同样,专栏的第一模块,我会简单介绍一下 Linux 有哪些系统调用,每一模块的第一节,我还会讲解这一模块的常用系统调用,以及如何编程调用这些系统调用。这样可以使你对 Linux 程序设计入个门,但是这对于实战肯定是远远不够的。如果要进一步学习 Linux 程序设计,推荐你阅读《UNIX 环境高级编程》,这本书有代码,有介绍,有原理,非常实用。
这块内容的辅助学习,我推荐一本《深入理解 LINUX 内核》。这本书言简意赅地讲述了主要的内核机制。看完这本书,你会对 Linux 内核有总体的了解。不过这本书的内核版本有点老,不过对于了解原理来讲,没有任何问题。
这里也推荐一本书,《LINUX 内核源代码情景分析》。这本书最大的优点是结合场景进行分析,看得见、摸得着,非常直观,唯一的缺点还是内核版本比较老。
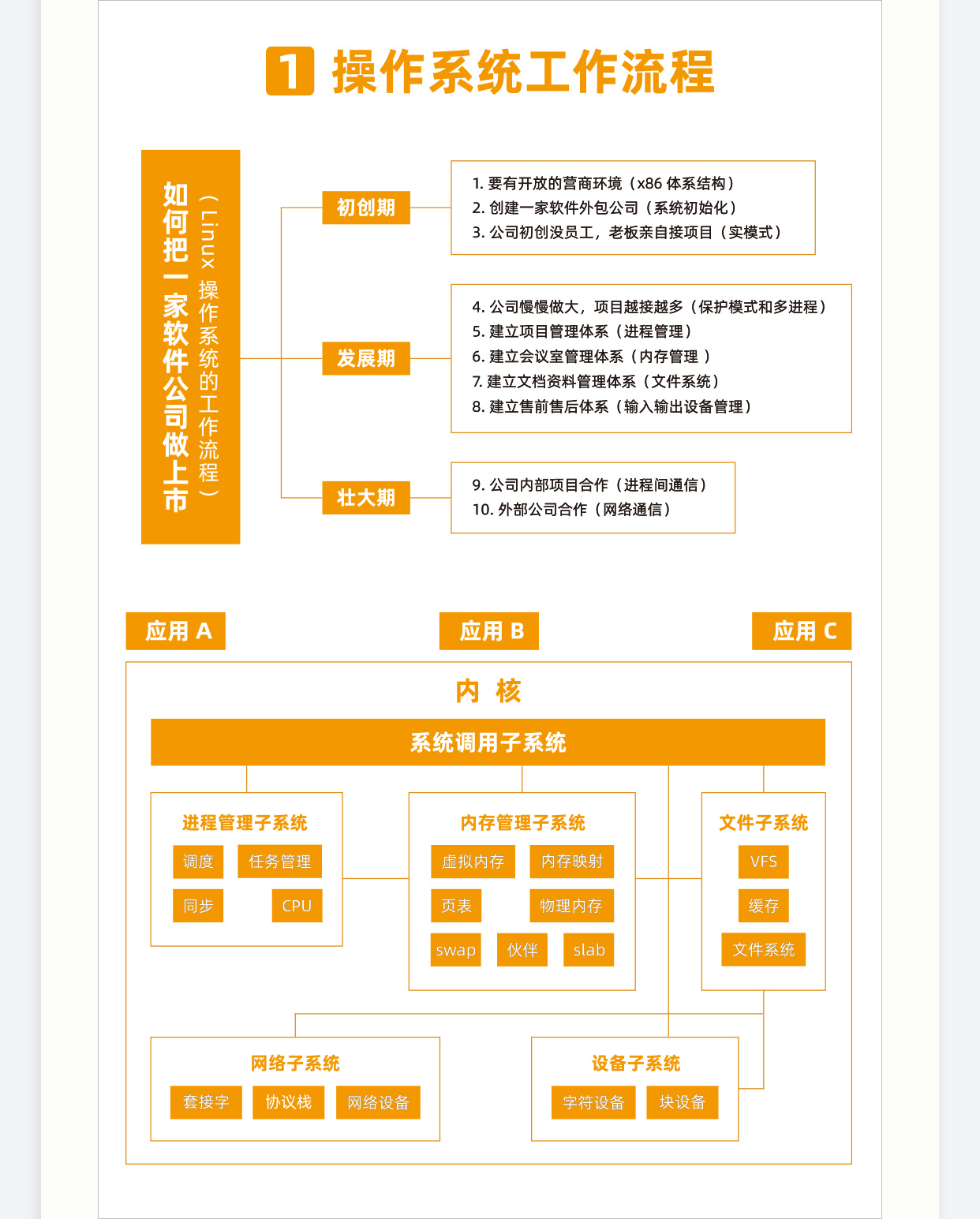
第一个坡:抛弃旧的思维习惯,熟练使用 Linux 命令行 第二个坡:通过系统调用或者 glibc,学会自己进行程序设计 第三个坡:了解 Linux 内核机制,反复研习重点突破 第四个坡:阅读 Linux 内核代码,聚焦核心逻辑和场景 第五个坡:实验定制化 Linux 组件,已经没人能阻挡你成为内核开发工程师了 最后一个坡:面向真实场景的开发,实践没有终点

Linux 一切皆文件
但是别忘了,Linux 里有一个特点,那就是一切皆文件。启动一个进程,需要一个程序文件,这是一个二进制文件。 启动的时候,要加载一些配置文件,例如 yml、properties 等,这是文本文件;启动之后会打印一些日志,如果写到硬盘上,也是文本文件。 但是如果我想把日志打印到交互控制台上,在命令行上唰唰地打印出来,这其实也是一个文件,是标准输出 stdout 文件。 这个进程的输出可以作为另一个进程的输入,这种方式称为管道,管道也是一个文件。 进程可以通过网络和其他进程进行通信,建立的 Socket,也是一个文件。 进程需要访问外部设备,设备也是一个文件。 文件都被存储在文件夹里面,其实文件夹也是一个文件。 进程运行起来,要想看到进程运行的情况,会在 /proc 下面有对应的进程号,还是一系列文件。
Linux 系统调用

- 进程树
- ps -ef: 用户进程不带中括号, 内核进程带中括号
- 用户进程祖先(1号进程, systemd); 内核进程祖先(2号进程, kthreadd)
- tty ? 一般表示后台服务
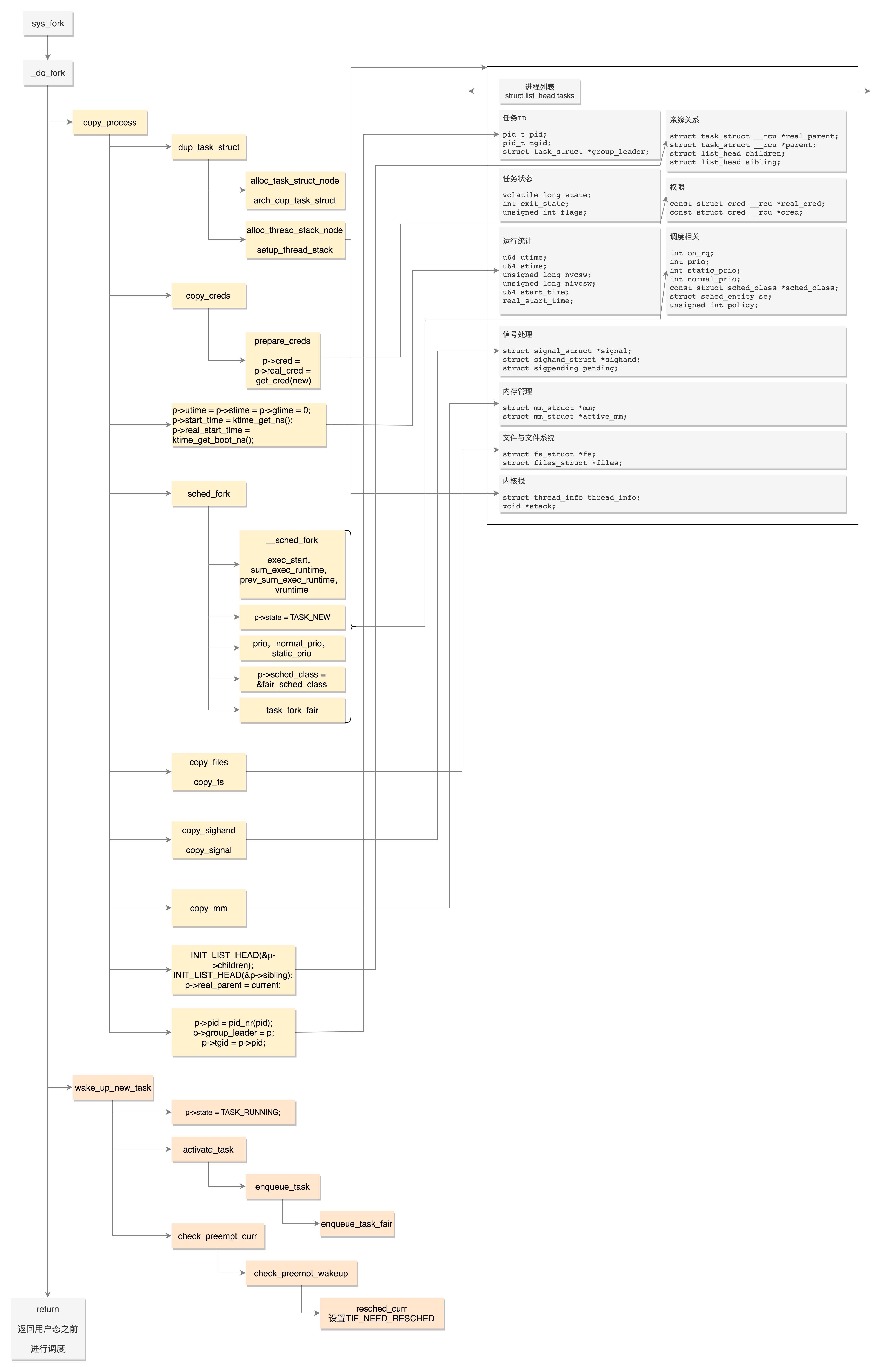
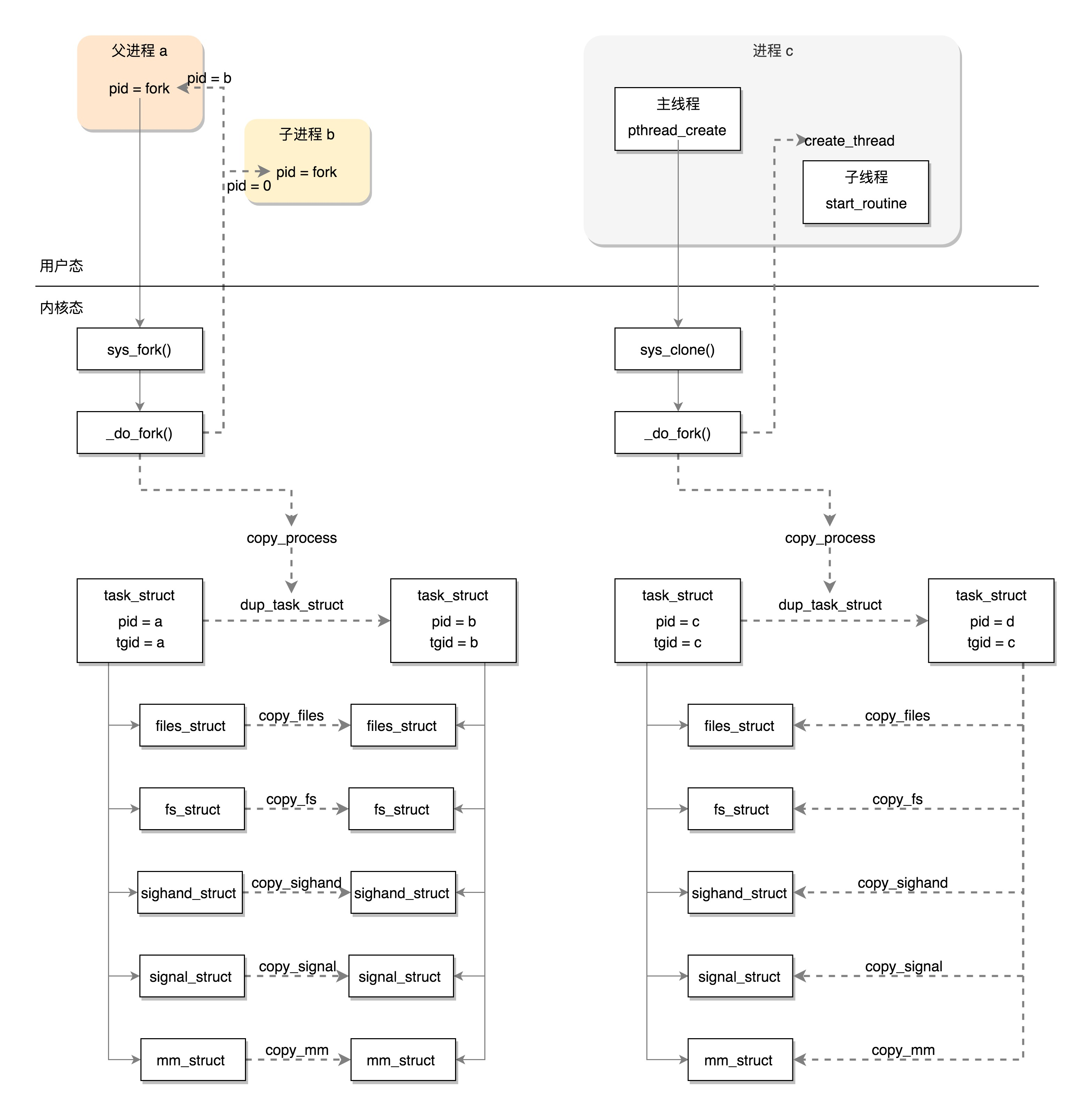
进程 和 线程
其实,对于任何一个进程来讲,即便我们没有主动去创建线程,进程也是默认有一个主线程的。线程是负责执行二进制指令的,它会根据项目执行计划书,一行一行执行下去。进程要比线程管的宽多了,除了执行指令之外,内存、文件系统等等都要它来管。
所以,进程相当于一个项目,而线程就是为了完成项目需求,而建立的一个个开发任务。默认情况下,你可以建一个大的任务,就是完成某某功能,然后交给一个人让它从头做到尾,这就是主线程。但是有时候,你发现任务是可以拆解的,如果相关性没有非常大前后关联关系,就可以并行执行。
例如,你接到了一个开发任务,要开发 200 个页面,最后组成一个网站。这时候你就可以拆分成 20 个任务,每个任务 10 个页面,并行开发。都开发完了,再做一次整合,这肯定比依次开发 200 个页面快多了。
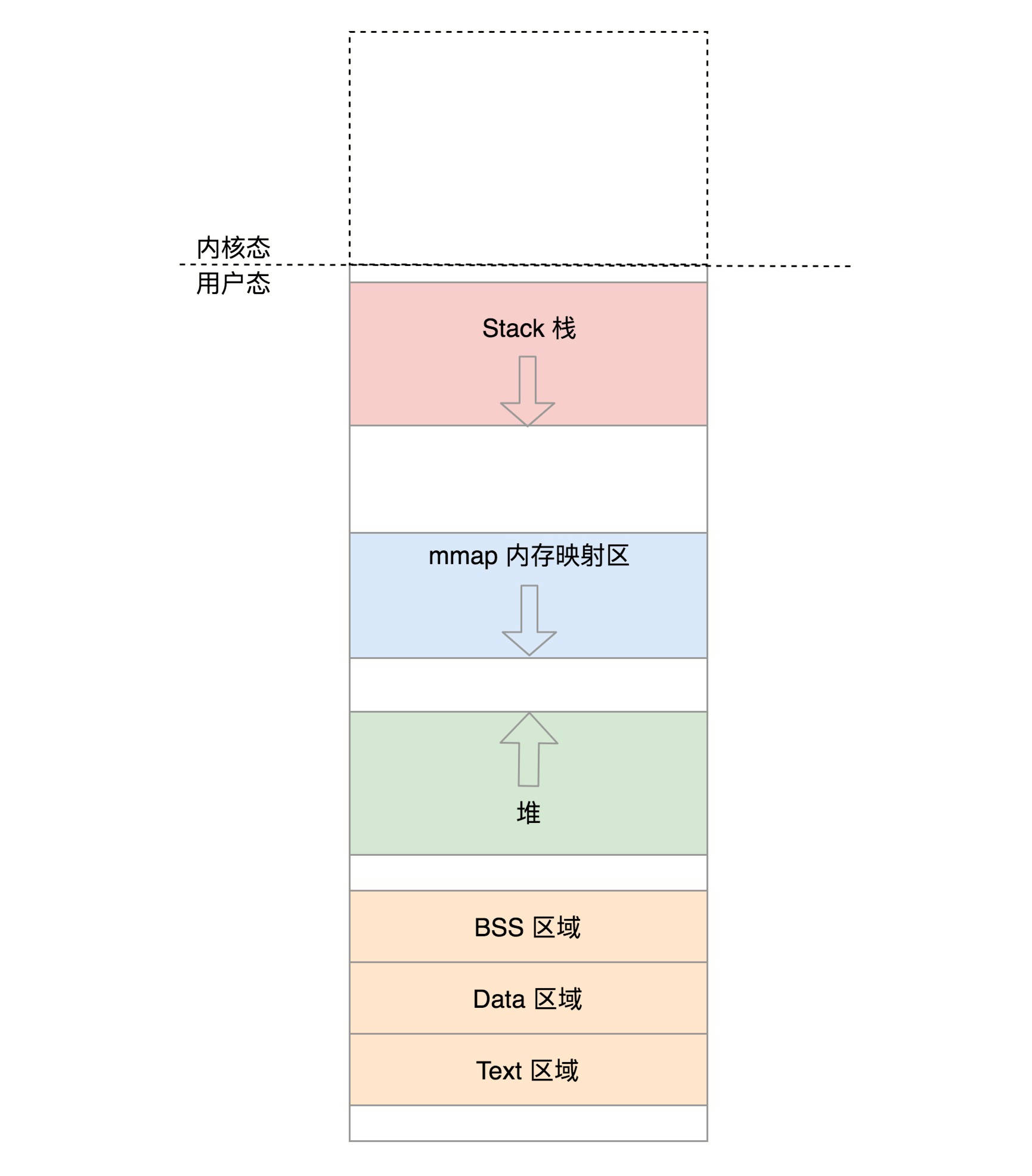
第一类是线程栈上的本地数据,比如函数执行过程中的局部变量。前面我们说过,函数的调用会使用栈的模型,这在线程里面是一样的。只不过每个线程都有自己的栈空间。栈的大小可以通过命令 ulimit -a 查看,默认情况下线程栈大小为 8192(8MB)。我们可以使用命令 ulimit -s 修改。
有的进程只有一个线程,有的进程有多个线程,它们都需要由内核分配 CPU 来干活。
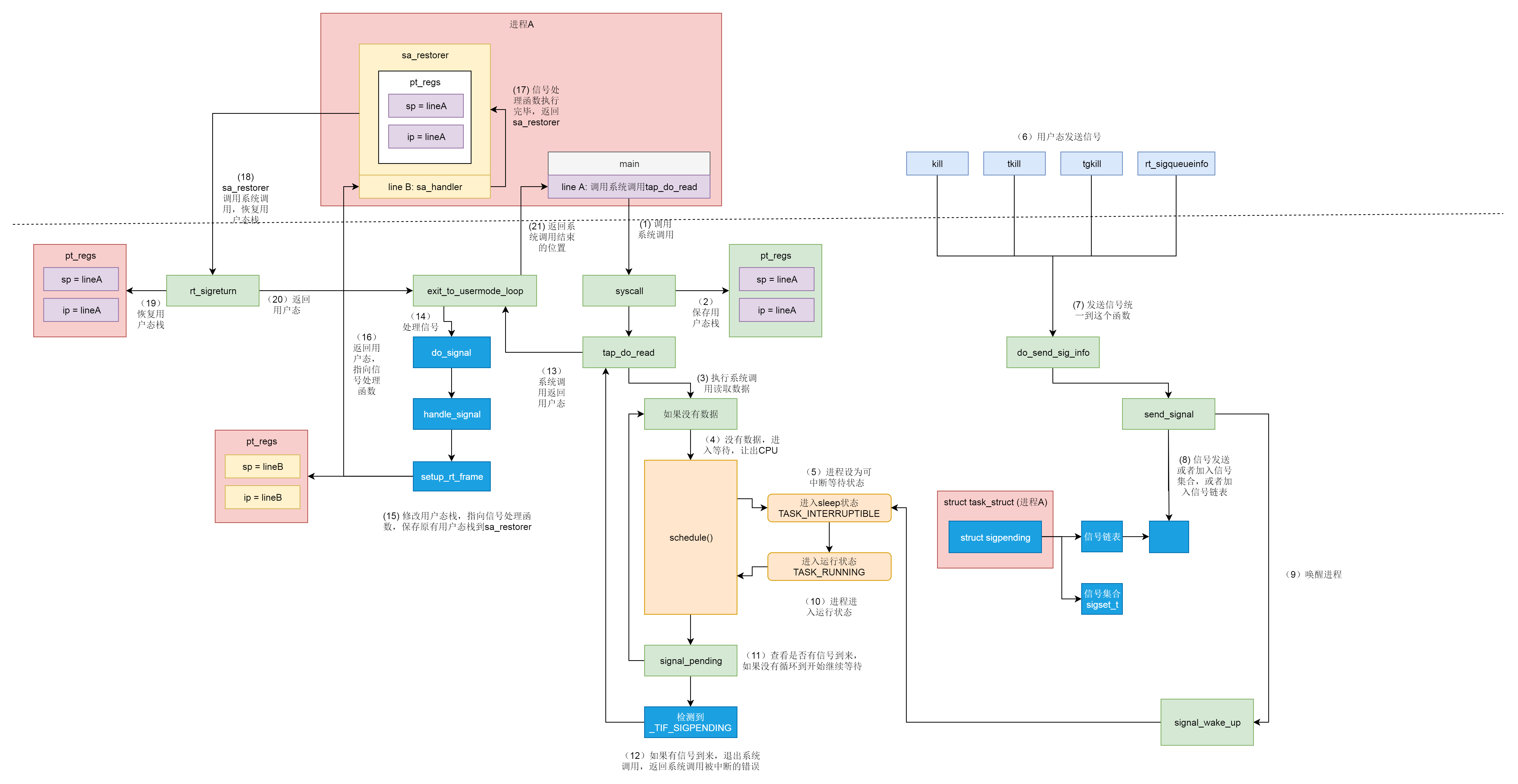
在 Linux 中,有两种睡眠状态。
一种是 TASK_INTERRUPTIBLE,可中断的睡眠状态。这是一种浅睡眠的状态,也就是说,虽然在睡眠,等待 I/O 完成,但是这个时候一个信号来的时候,进程还是要被唤醒。只不过唤醒后,不是继续刚才的操作,而是进行信号处理。当然程序员可以根据自己的意愿,来写信号处理函数,例如收到某些信号,就放弃等待这个 I/O 操作完成,直接退出;或者收到某些信息,继续等待。
另一种睡眠是 TASK_UNINTERRUPTIBLE,不可中断的睡眠状态。这是一种深度睡眠状态,不可被信号唤醒,只能死等 I/O 操作完成。一旦 I/O 操作因为特殊原因不能完成,这个时候,谁也叫不醒这个进程了。你可能会说,我 kill 它呢?别忘了,kill 本身也是一个信号,既然这个状态不可被信号唤醒,kill 信号也被忽略了。除非重启电脑,没有其他办法。
于是,我们就有了一种新的进程睡眠状态,TASK_KILLABLE,可以终止的新睡眠状态。进程处于这种状态中,它的运行原理类似 TASK_UNINTERRUPTIBLE,只不过可以响应致命信号。
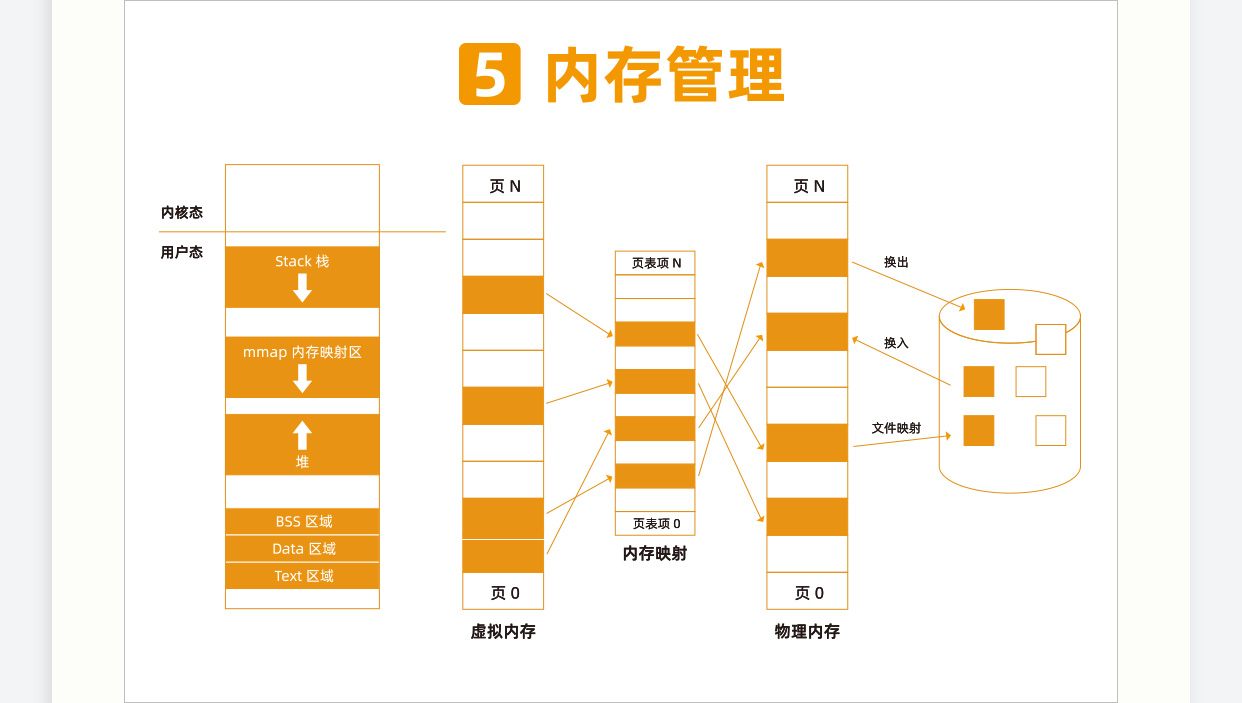
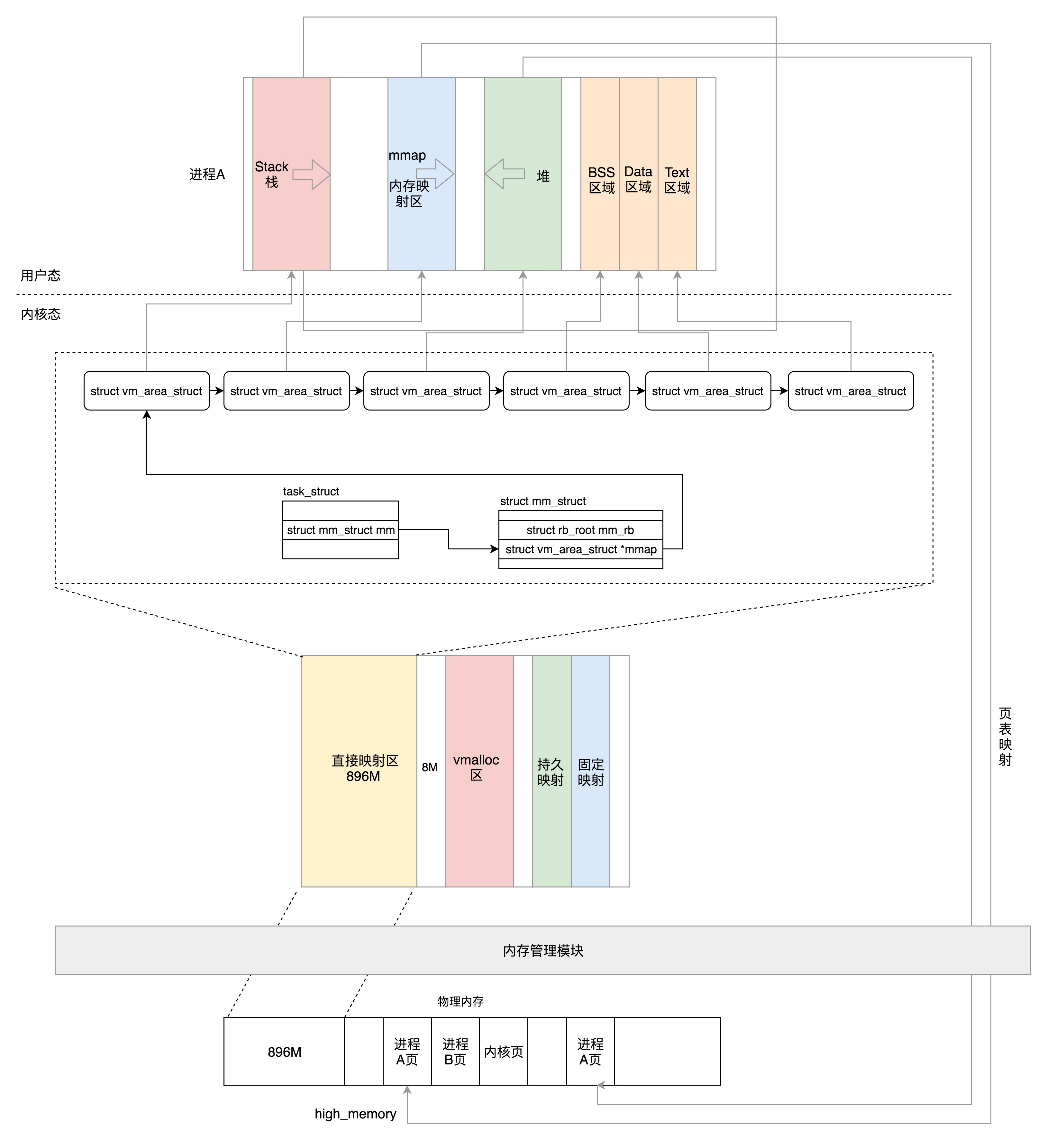
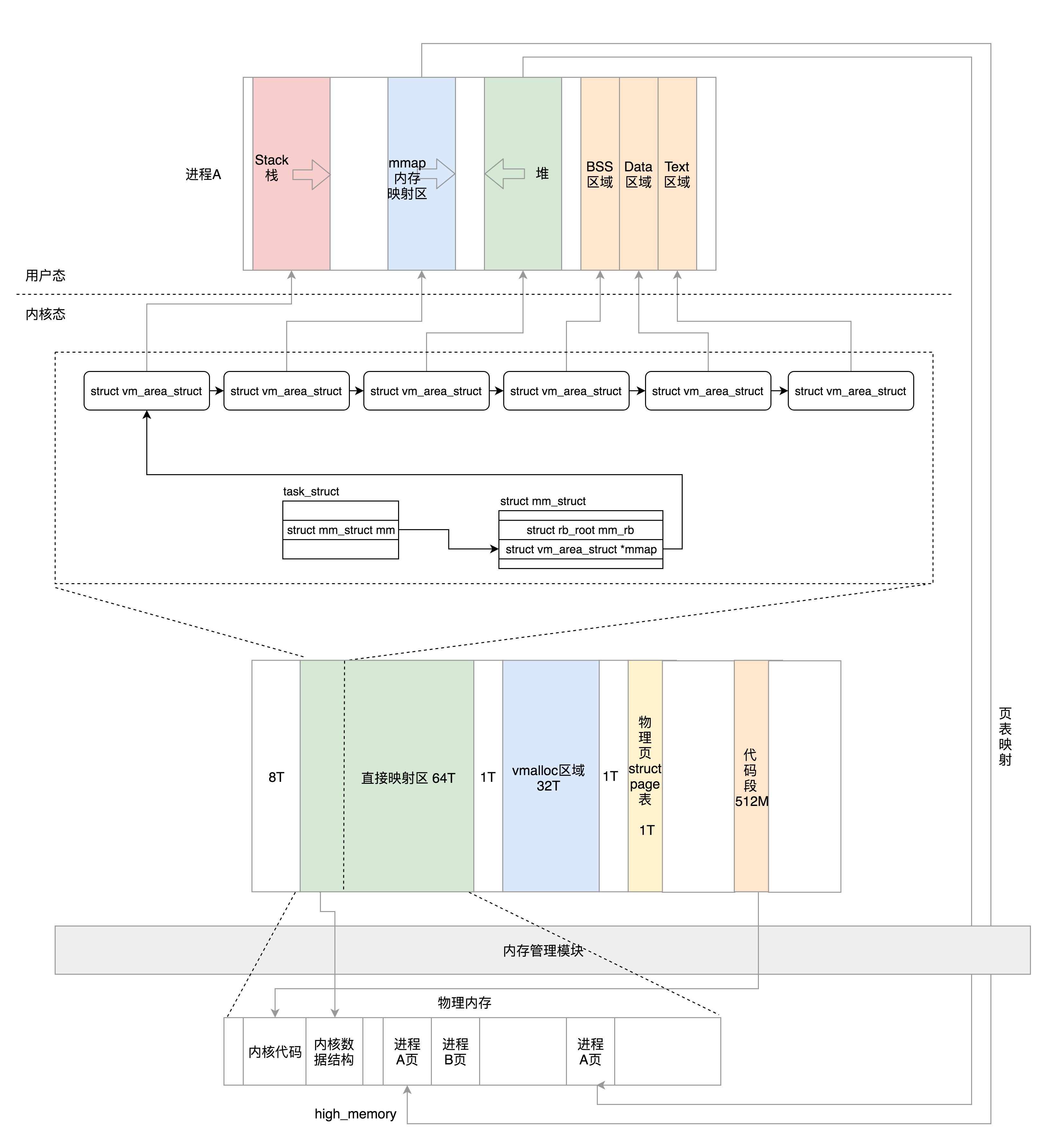
内存管理
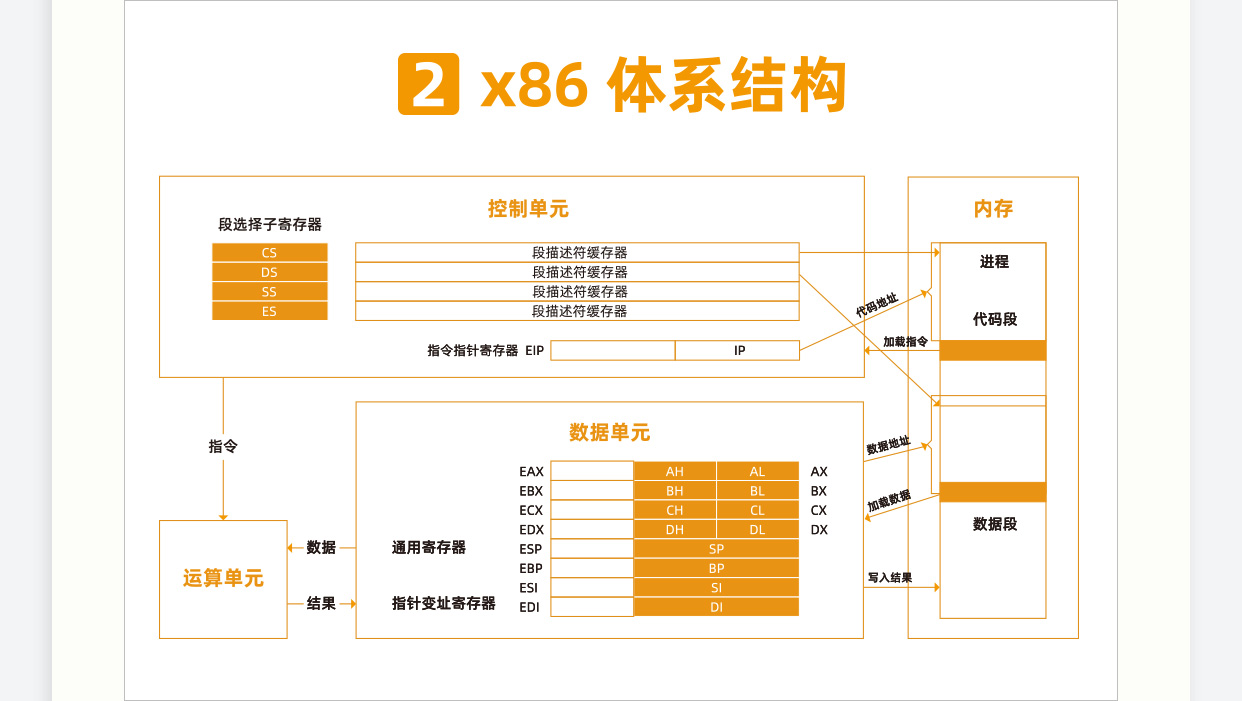
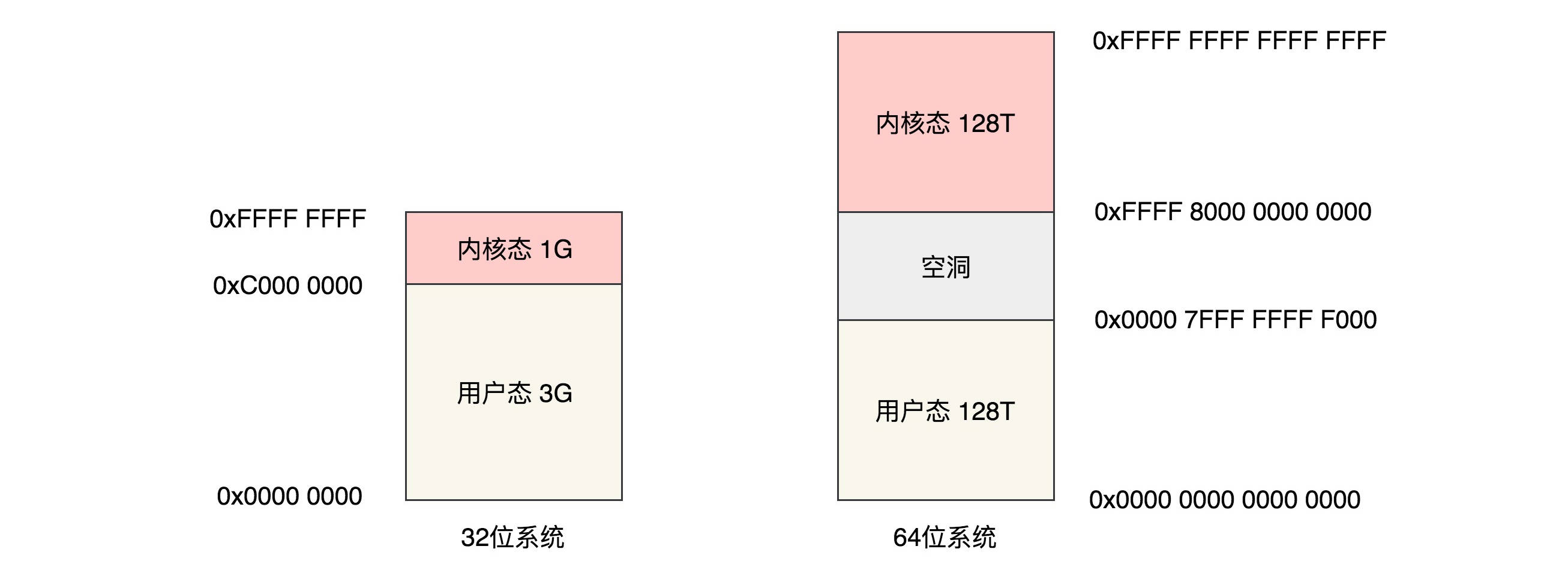
第一,虚拟内存空间的管理,每个进程看到的是独立的、互不干扰的虚拟地址空间; 第二,物理内存的管理,物理内存地址只有内存管理模块能够使用; 第三,内存映射,需要将虚拟内存和物理内存映射、关联起来。
这一节我们讲了分段机制、分页机制以及从虚拟地址到物理地址的映射方式。总结一下这两节,我们可以把内存管理系统精细化为下面三件事情:
第一,虚拟内存空间的管理,将虚拟内存分成大小相等的页; 第二,物理内存的管理,将物理内存分成大小相等的页; 第三,内存映射,将虚拟内存页和物理内存页映射起来,并且在内存紧张的时候可以换出到硬盘中。

这一节我们说一个页的大小为 4K,有时候我们需要为应用配置大页(HugePage)。请你查一下大页的大小及配置方法,咱们后面会用到。

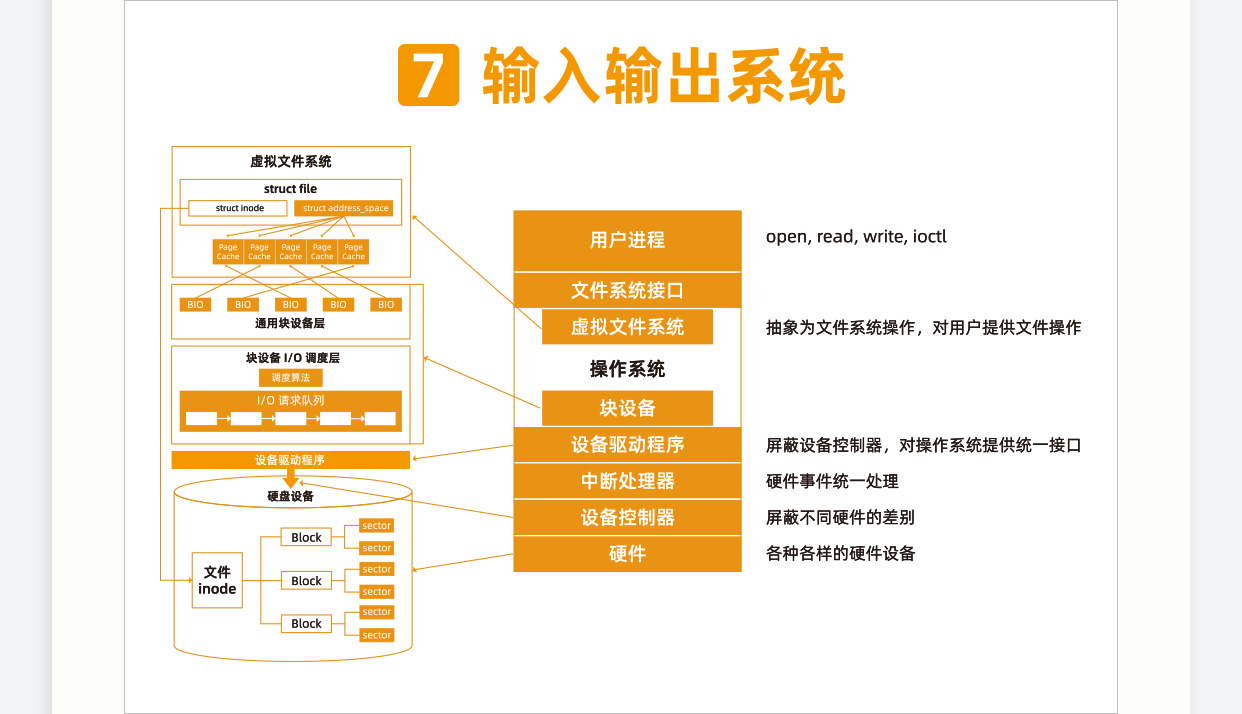
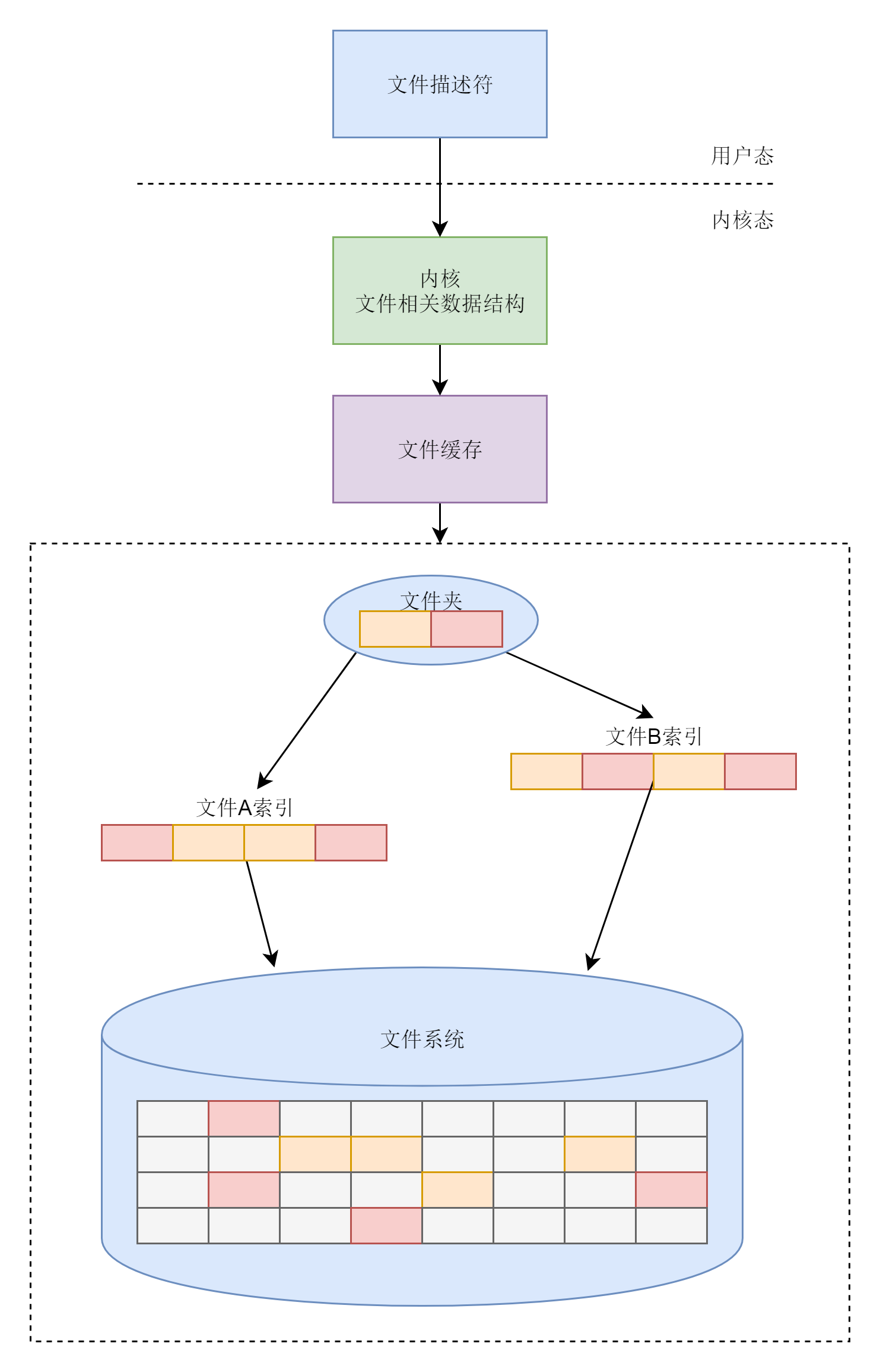
文件系统
进程间通信
管道模型
ps -ef | grep 关键字 | awk '{print $2}' | xargs kill -9
这里面的竖线“|”就是一个管道。它会将前一个命令的输出,作为后一个命令的输入。从管道的这个名称可以看出来,管道是一种单向传输数据的机制,它其实是一段缓存,里面的数据只能从一端写入,从另一端读出。如果想互相通信,我们需要创建两个管道才行。
管道分为两种类型,“|” 表示的管道称为匿名管道,意思就是这个类型的管道没有名字,用完了就销毁了。就像上面那个命令里面的一样,竖线代表的管道随着命令的执行自动创建、自动销毁。用户甚至都不知道自己在用管道这种技术,就已经解决了问题。所以这也是面试题里面经常会问的,到时候千万别说这是竖线,而要回答背后的机制,管道。
mkfifo hello
# ls -l
prw-r--r-- 1 root root 0 May 21 23:29 hello
# echo "hello world" > hello
消息队列模型
共享内存模型
信号量
# kill -l
man 7 signal
Signal Value Action Comment
──────────────────────────────────────────────────────────────────────
SIGHUP 1 Term Hangup detected on controlling terminal
or death of controlling process
SIGINT 2 Term Interrupt from keyboard
SIGQUIT 3 Core Quit from keyboard
SIGILL 4 Core Illegal Instruction
SIGABRT 6 Core Abort signal from abort(3)
SIGFPE 8 Core Floating point exception
SIGKILL 9 Term Kill signal
SIGSEGV 11 Core Invalid memory reference
SIGPIPE 13 Term Broken pipe: write to pipe with no
readers
SIGALRM 14 Term Timer signal from alarm(2)
SIGTERM 15 Term Termination signal
SIGUSR1 30,10,16 Term User-defined signal 1
SIGUSR2 31,12,17 Term User-defined signal 2
……
所谓的匿名管道,其实就是内核里面的一串缓存。

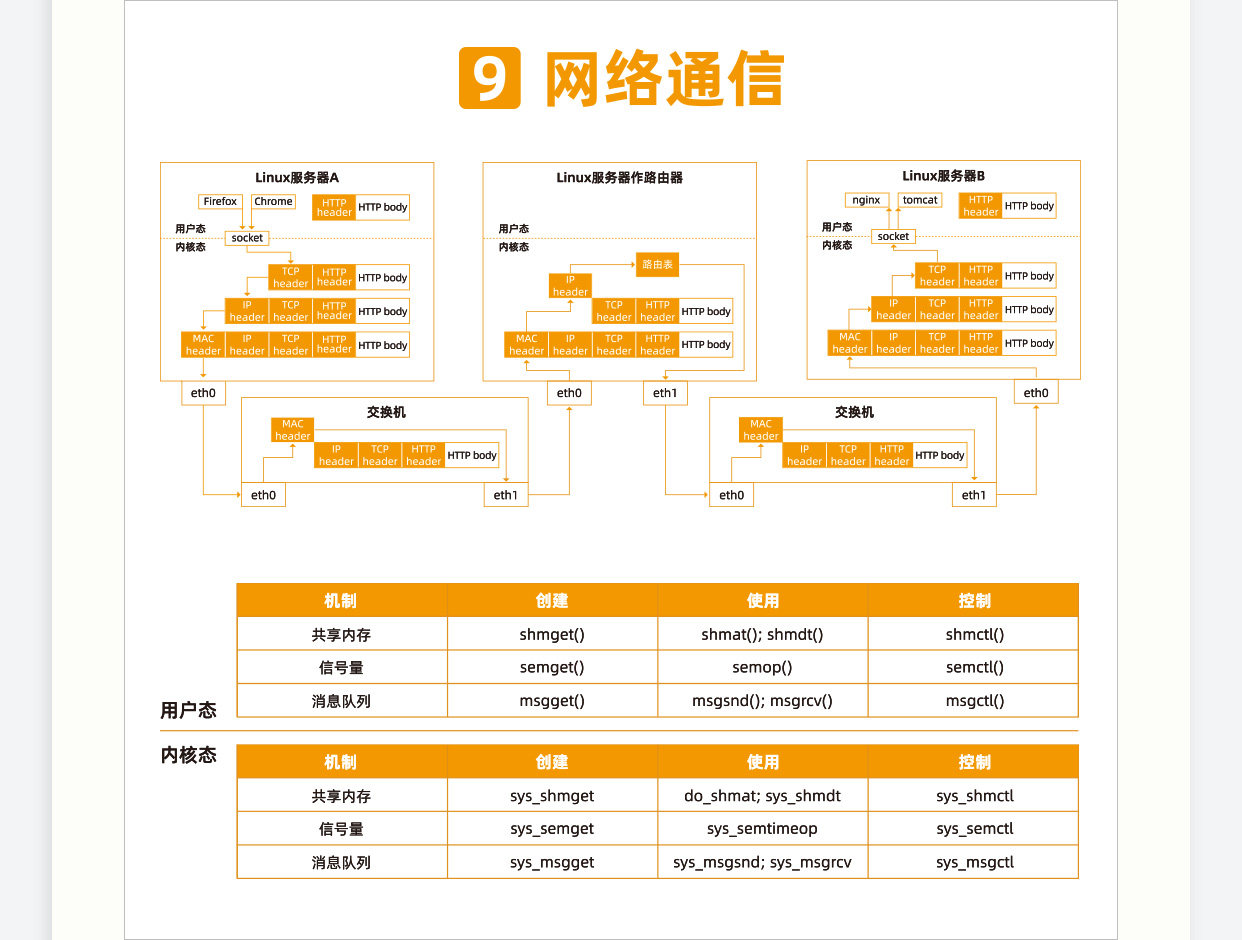
网络系统
上一节我们讲的进程间通信,其实是通过内核的数据结构完成的,主要用于在一台 Linux 上两个进程之间的通信。但是,一旦超出一台机器的范畴,我们就需要一种跨机器的通信机制。
一台机器将自己想要表达的内容,按照某种约定好的格式发送出去,当另外一台机器收到这些信息后,也能够按照约定好的格式解析出来,从而准确、可靠地获得发送方想要表达的内容。这种约定好的格式就是网络协议(Networking Protocol)。
我们将要讲的 Socket 通信以及相关的系统调用、内核机制,都是基于网络协议的,如果不了解网络协议的机制,解析 Socket 的过程中,你就会迷失方向,因此这一节,我们有必要做一个预习,先来大致讲一下网络协议的基本原理。
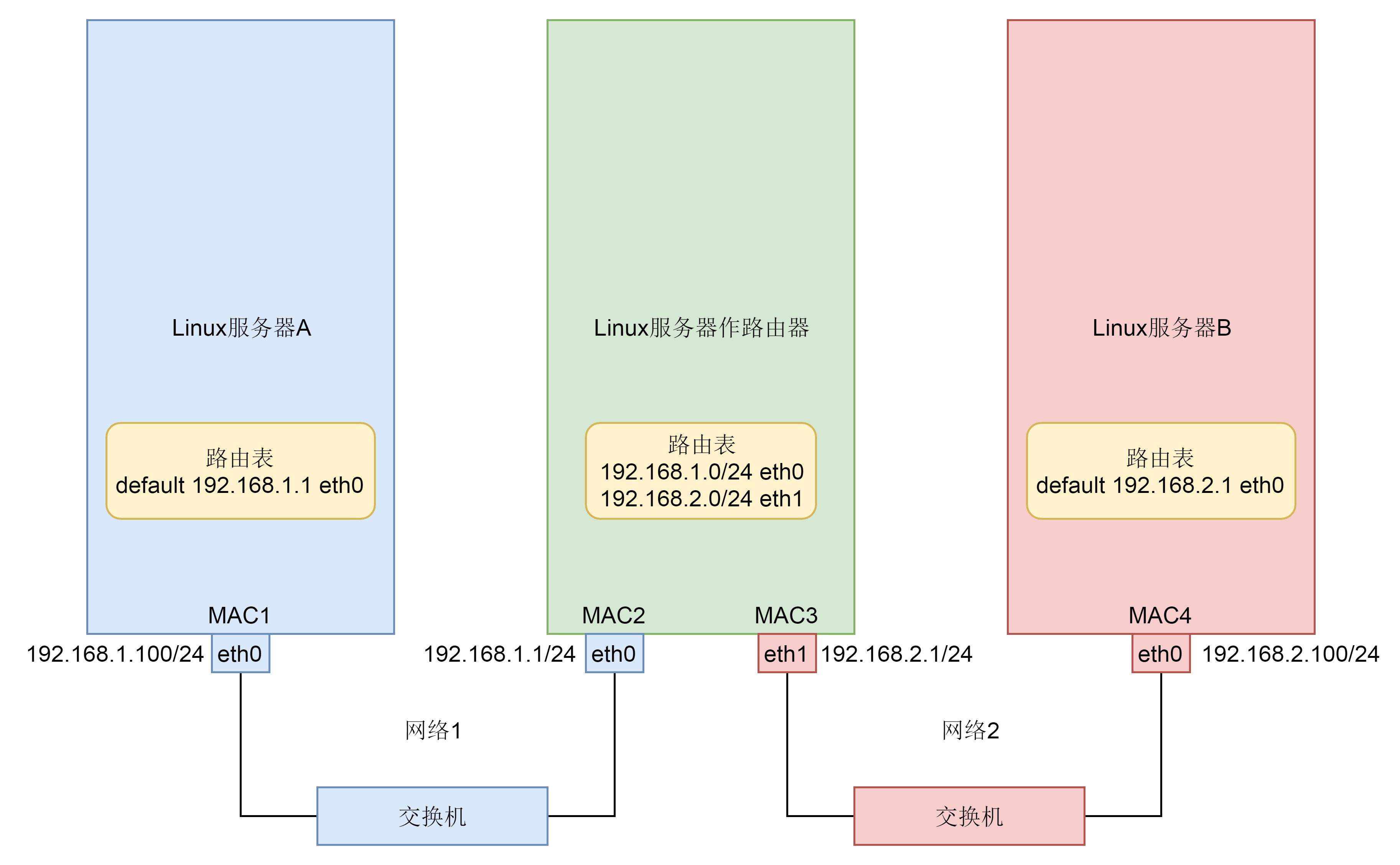
说到网络协议,我们还需要简要介绍一下两种网络协议模型,一种是 OSI 的标准七层模型,一种是业界标准的 TCP/IP 模型。它们的对应关系如下图所示:
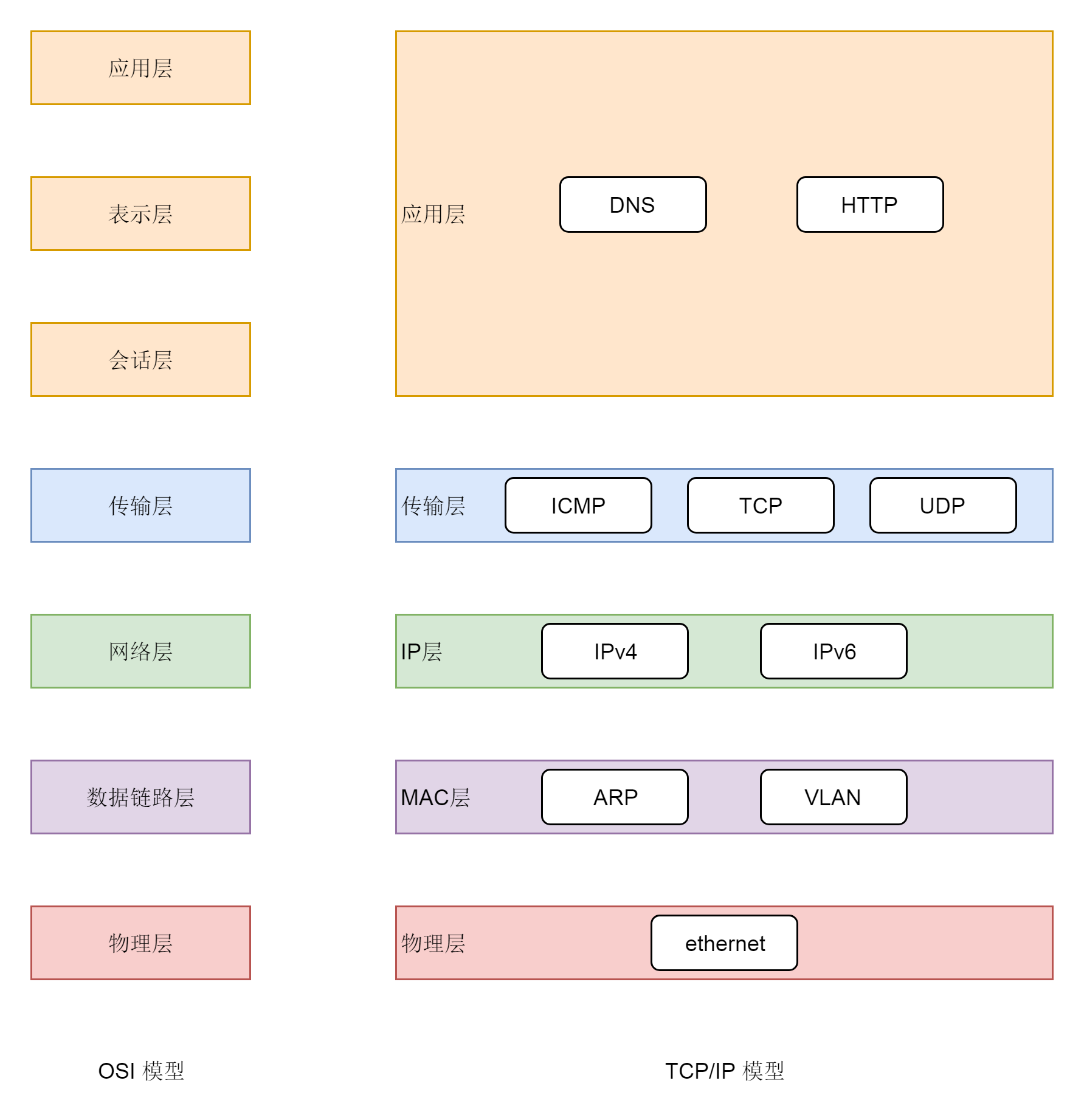
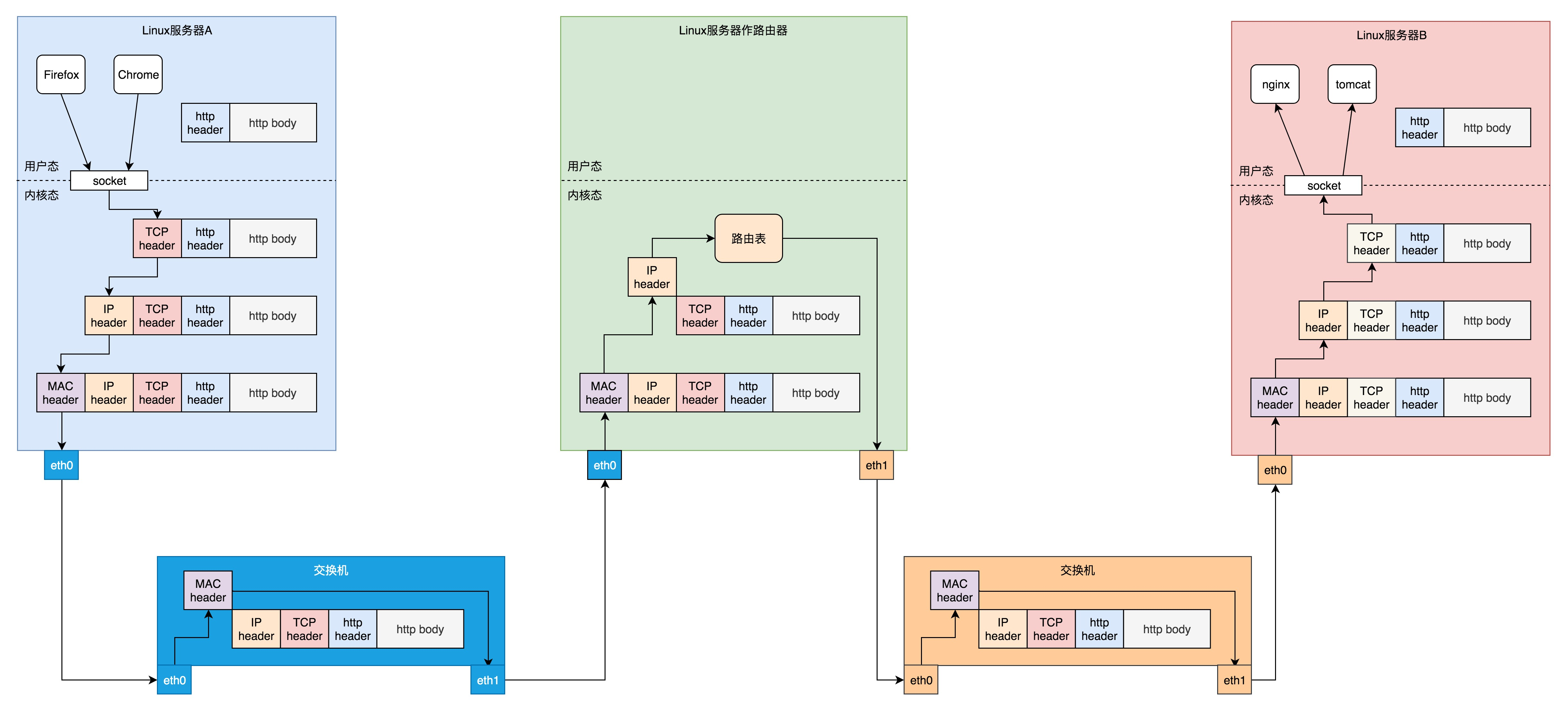
二层到四层都是在 Linux 内核里面处理的,应用层例如浏览器、Nginx、Tomcat 都是用户态的。内核里面对于网络包的处理是不区分应用的。
从四层再往上,就需要区分网络包发给哪个应用。在传输层的 TCP 和 UDP 协议里面,都有端口的概念,不同的应用监听不同的端口。例如,服务端 Nginx 监听 80、Tomcat 监听 8080;再如客户端浏览器监听一个随机端口,FTP 客户端监听另外一个随机端口。
应用层和内核互通的机制,就是通过 Socket 系统调用。所以经常有人会问,Socket 属于哪一层,其实它哪一层都不属于,它属于操作系统的概念,而非网络协议分层的概念。只不过操作系统选择对于网络协议的实现模式是,二到四层的处理代码在内核里面,七层的处理代码让应用自己去做,两者需要跨内核态和用户态通信,就需要一个系统调用完成这个衔接,这就是 Socket。
TCP 是面向连接的,UDP 是面向无连接的。 TCP 提供可靠交付,无差错、不丢失、不重复、并且按序到达;UDP 不提供可靠交付,不保证不丢失,不保证按顺序到达。 TCP 是面向字节流的,发送时发的是一个流,没头没尾;UDP 是面向数据报的,一个一个地发送。 TCP 是可以提供流量控制和拥塞控制的,既防止对端被压垮,也防止网络被压垮。

服务端所在的服务器可能有多个网卡、多个地址,可以选择监听在一个地址,也可以监听 0.0.0.0 表示所有的地址都监听。服务端一般要监听在一个众所周知的端口上,例如,Nginx 一般是 80,Tomcat 一般是 8080。
客户端要访问服务端,肯定事先要知道服务端的端口。无论是电商,还是游戏,还是视频,如果你仔细观察,会发现都有一个这样的端口。可能你会发现,客户端不需要 bind,因为浏览器嘛,随机分配一个端口就可以了,只有你主动去连接别人,别人不会主动连接你,没有人关心客户端监听到了哪里。
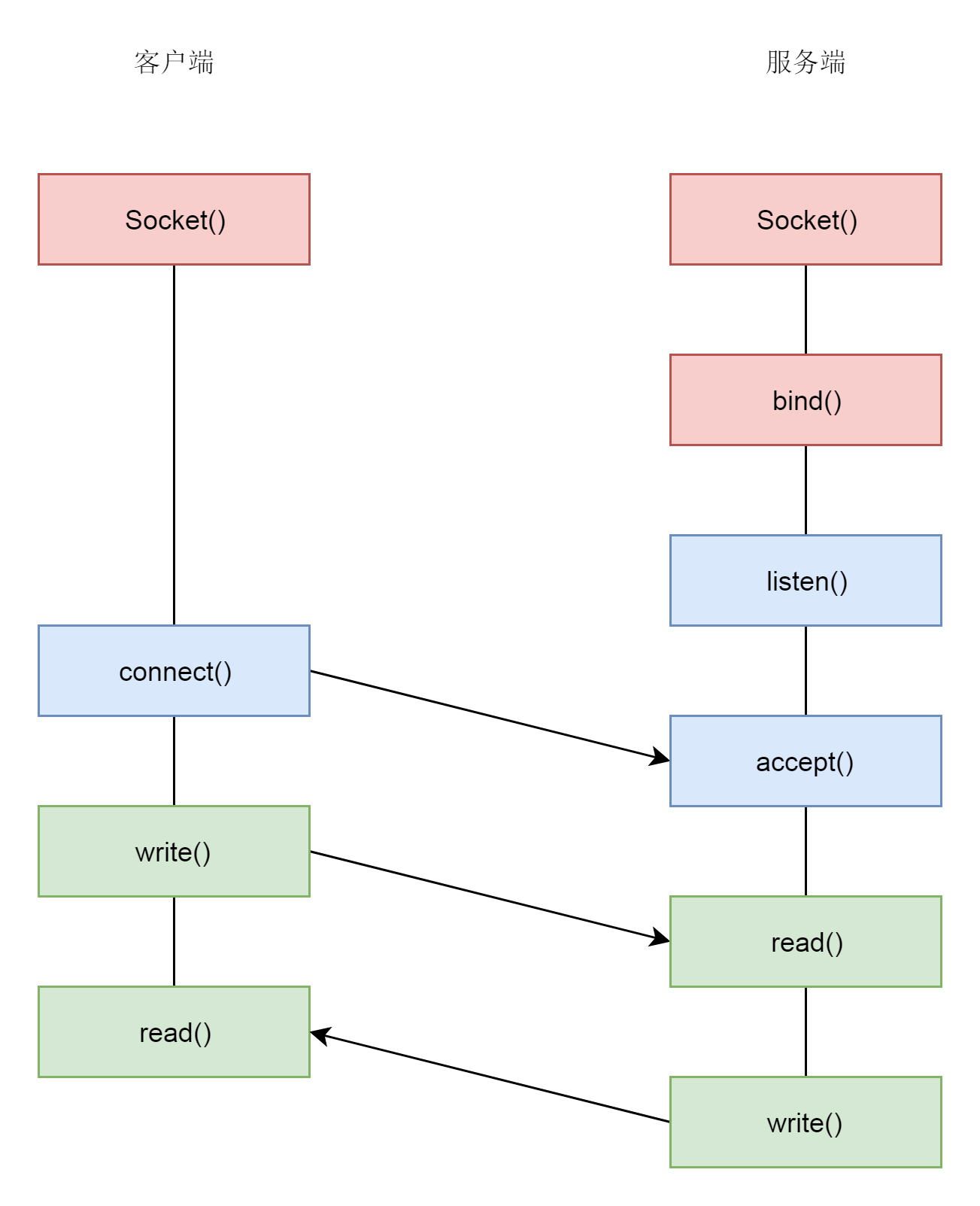
接下来,就要建立 TCP 的连接了,也就是著名的三次握手,其实就是将客户端和服务端的状态通过三次网络交互,达到初始状态是协同的状态。下图就是三次握手的序列图以及对应的状态转换。
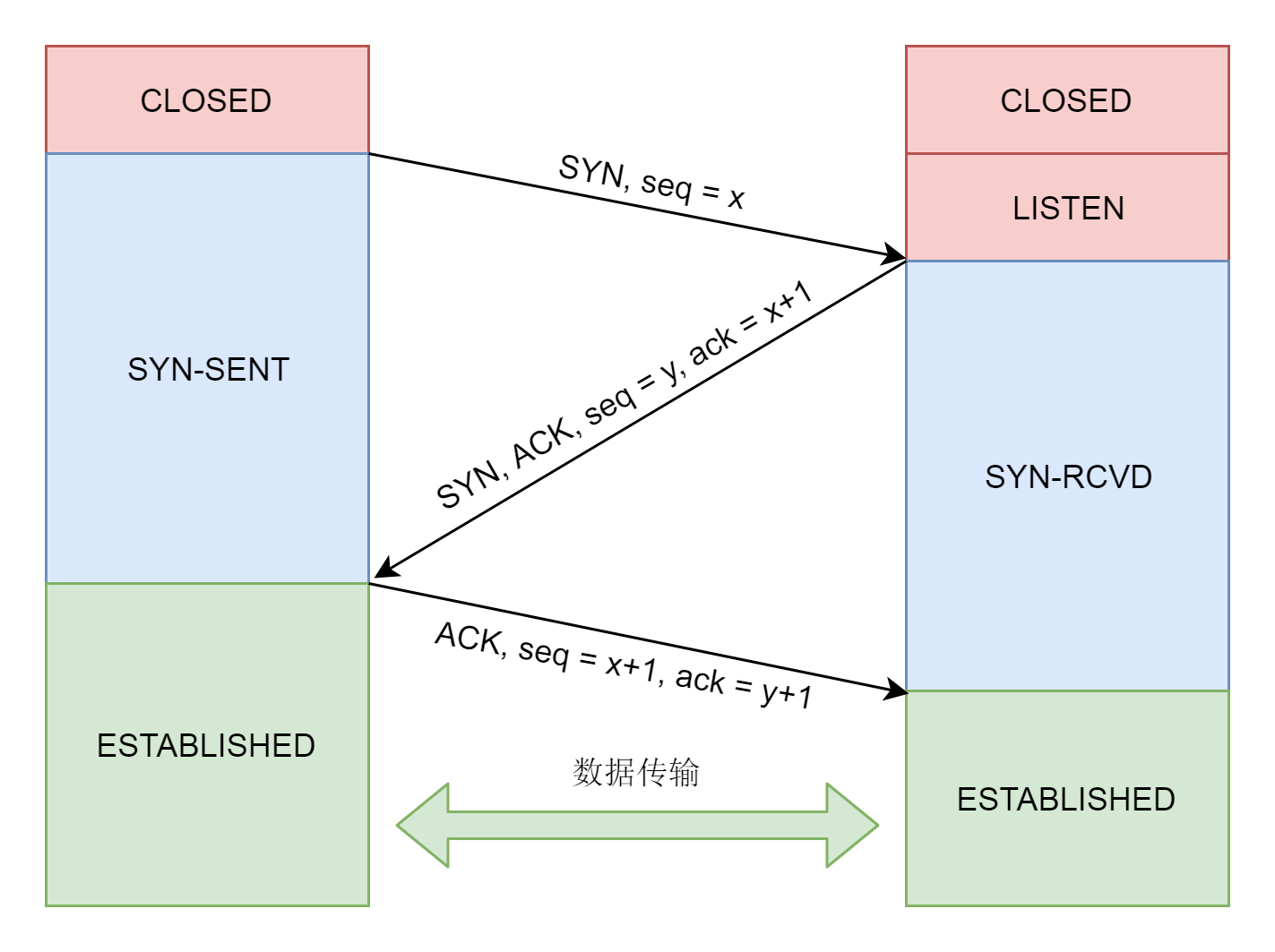
连接的建立过程,也即三次握手,是 TCP 层的动作,是在内核完成的,应用层不需要参与。
UDP 是没有连接的,所以不需要三次握手,也就不需要调用 listen 和 connect,但是 UDP 的交互仍然需要 IP 地址和端口号,因而也需要 bind。


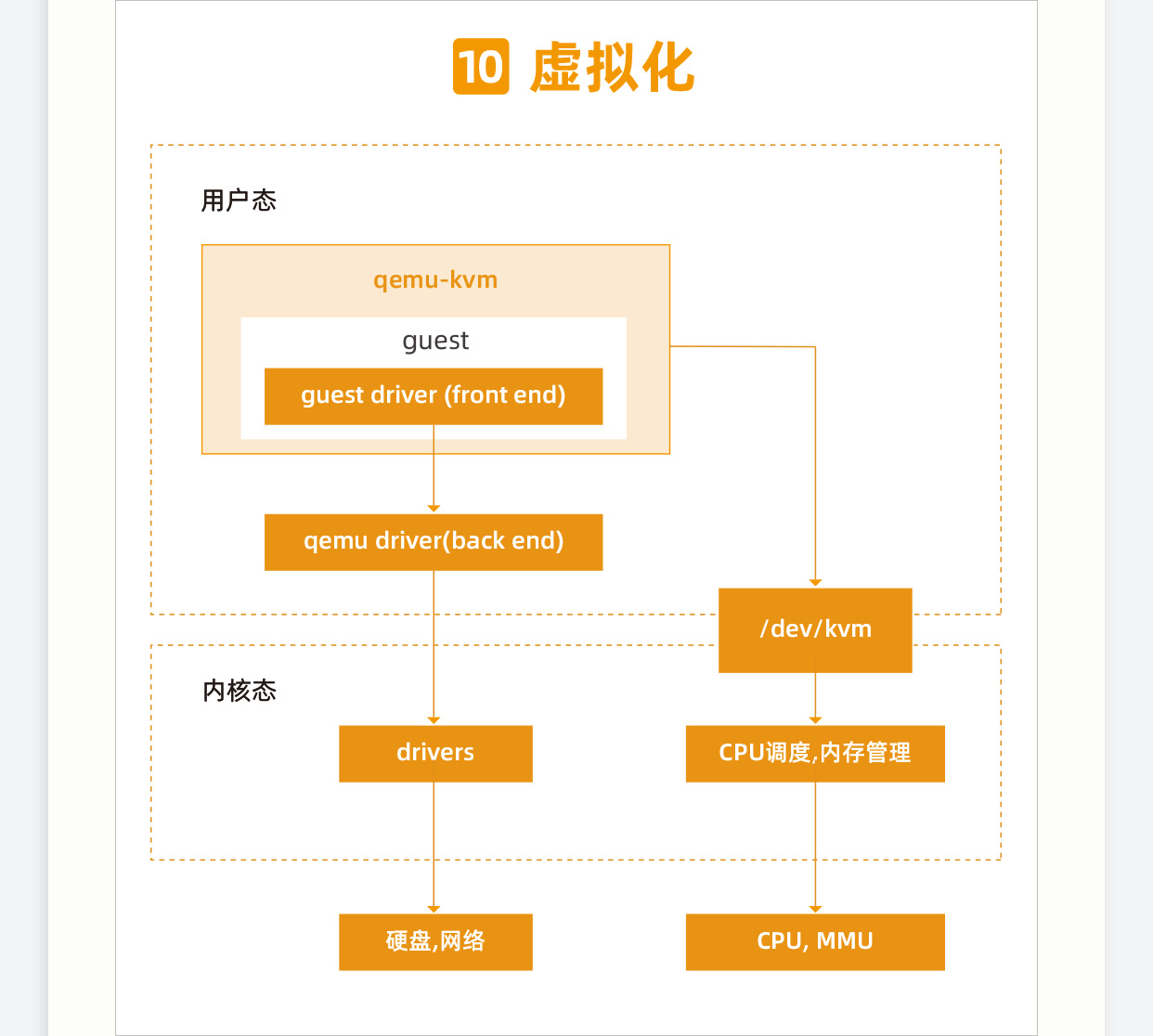
虚拟化
公司大有大的好处,自然也有大的毛病,也就是咱们常见的“大公司病”——不灵活。这里面的不灵活,有下面这几种,我列一下,你看看你是不是都见过。
资源大小不灵活:有时候我们不需要这么大规格的机器,可能只想尝试一下某些新业务,申请个 4 核 8G 的服务器试一下,但是不可能采购这么小规格的机器。无论每个项目需要多大规格的机器,公司统一采购就限制几种,全部是上面那种大规格的。
资源申请不灵活:规格定死就定死吧,可是每次申请机器都要重新采购,周期很长。
资源复用不灵活:反正我需要的资源不多,和别人共享一台机器吧,这样不同的进程可能会产生冲突,例如 socket 的端口冲突。另外就是别人用过的机器,不知道上面做过哪些操作,有很多的历史包袱,如果重新安装则代价太大。


但是,怎么解决权限等级的问题呢?于是,Intel 的 VT-x 和 AMD 的 AMD-V 从硬件层面帮上了忙。当初谁让你们这些写内核的大牛用等级这么奢侈,用完了 0,就是 3,也不省着点儿用,没办法,只好另起炉灶弄一个新的标志位,表示当前是在虚拟机状态下,还是在真正的物理机内核下。
对于虚拟机内核来讲,只要将标志位设为虚拟机状态,我们就可以直接在 CPU 上执行大部分的指令,不需要虚拟化软件在中间转述,除非遇到特别敏感的指令,才需要将标志位设为物理机内核态运行,这样大大提高了效率。
所以,安装虚拟机的时候,我们务必要将物理 CPU 的这个标志位打开。想知道是否打开,对于 Intel,你可以查看 grep “vmx” /proc/cpuinfo;对于 AMD,你可以查看 grep “svm” /proc/cpuinfo
这叫作硬件辅助虚拟化(Hardware-Assisted Virtualization)。
所以,KVM 在内核里面需要有一个模块,来设置当前 CPU 是 Guest OS 在用,还是 Host OS 在用。
下面,我们来查看内核模块中是否含有 kvm, lsmod | grep kvm。
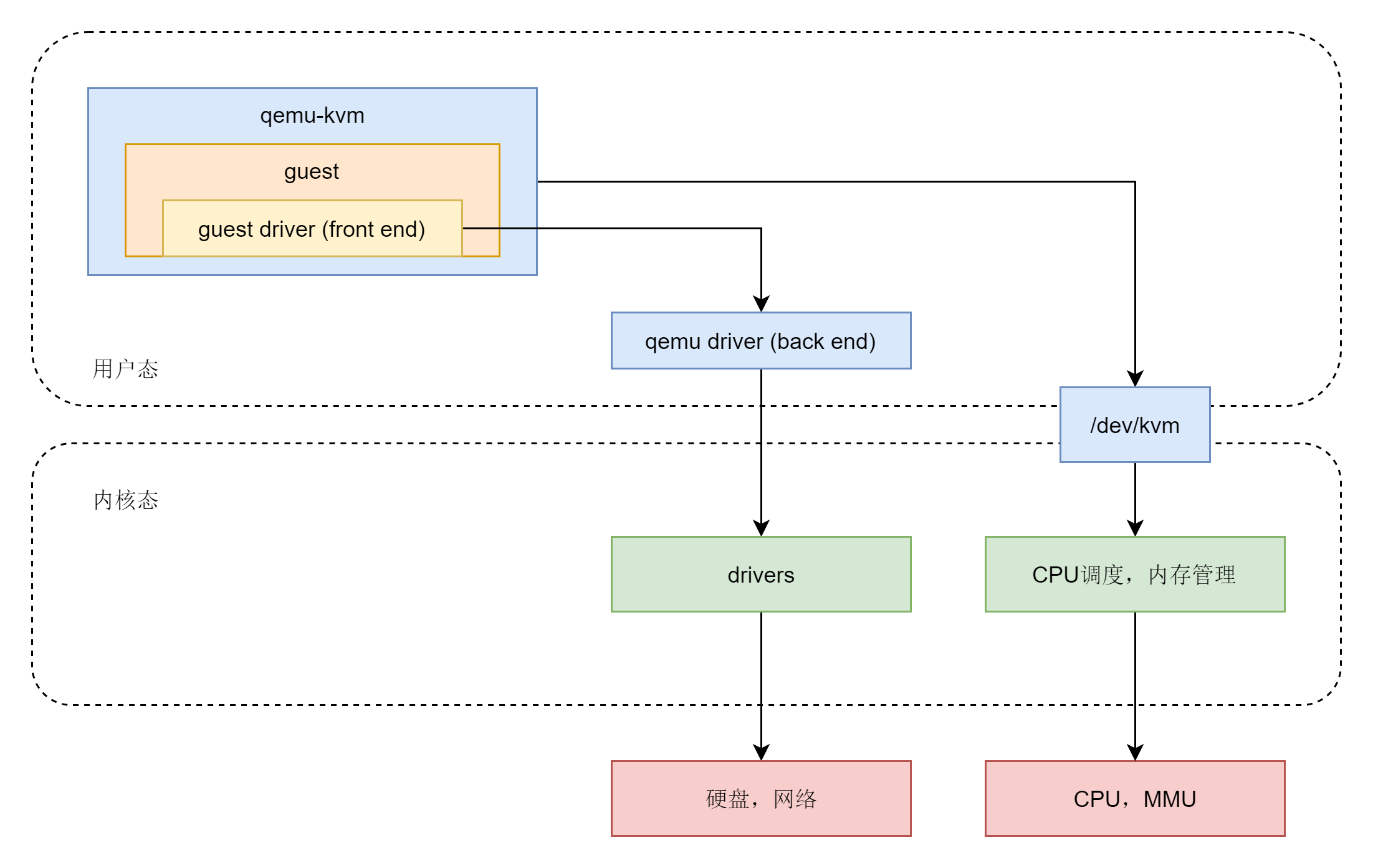
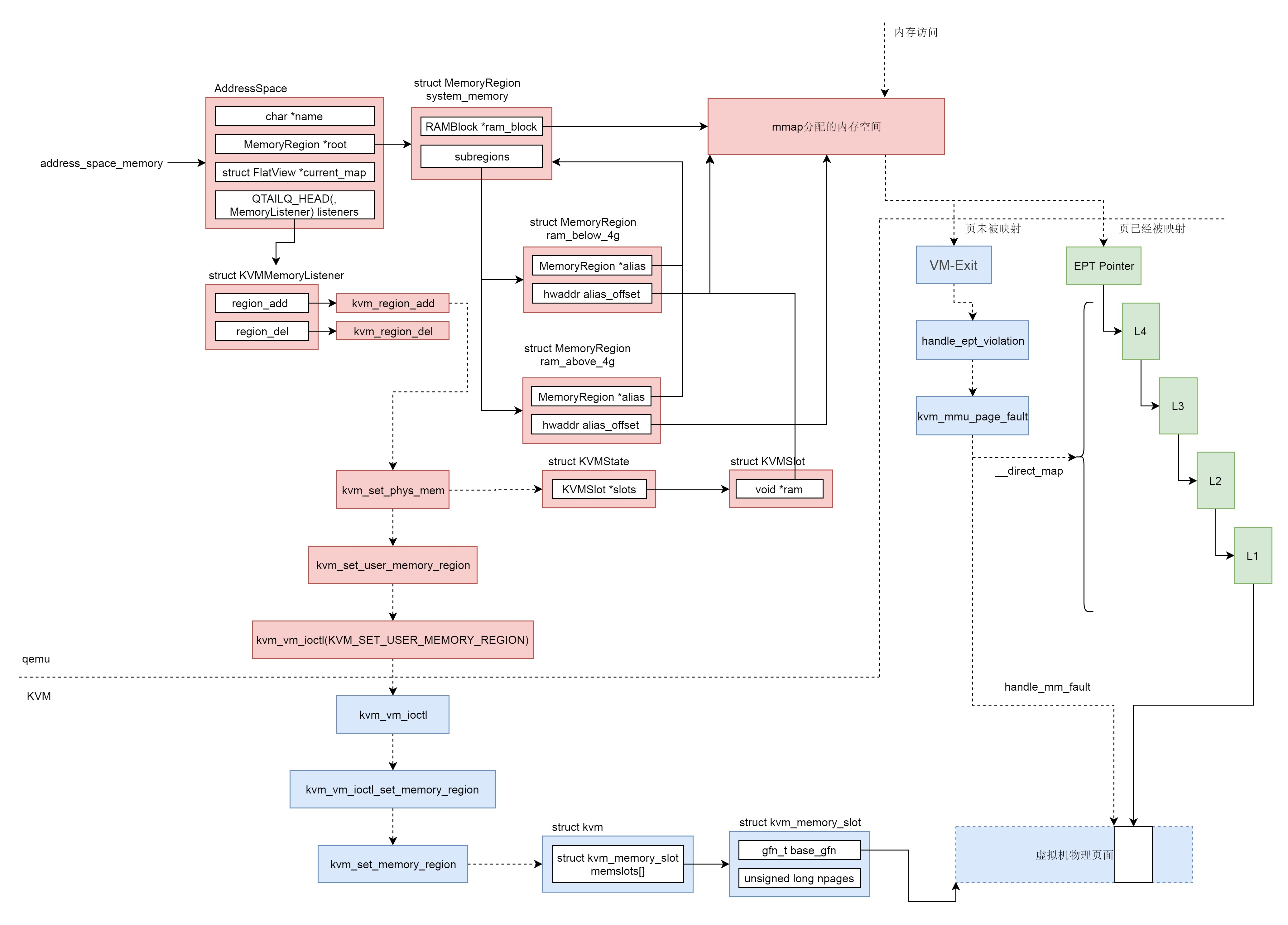
上一节,我们解析了计算虚拟化之 CPU。可以看到,CPU 的虚拟化是用户态的 qemu 和内核态的 KVM 共同配合完成的。它们二者通过 ioctl 进行通信。对于内存管理来讲,也是需要这两者配合完成的。