赵成的运维体系管理课
https://time.geekbang.org/column/intro/63
精华总结
所以,从运维的范畴上来讲,我认为,一个研发团队内,除去业务需求实现层面的事情,其它都是运维的范畴,这个范畴内的事情本质上都是在为软件生命周期中的运行维护阶段服务
在微服务的架构模式下,我们的运维视角一定转到应用这个核心概念上来,一切要从应用的角度来分析和看待问题。
基础设施层面的标准化
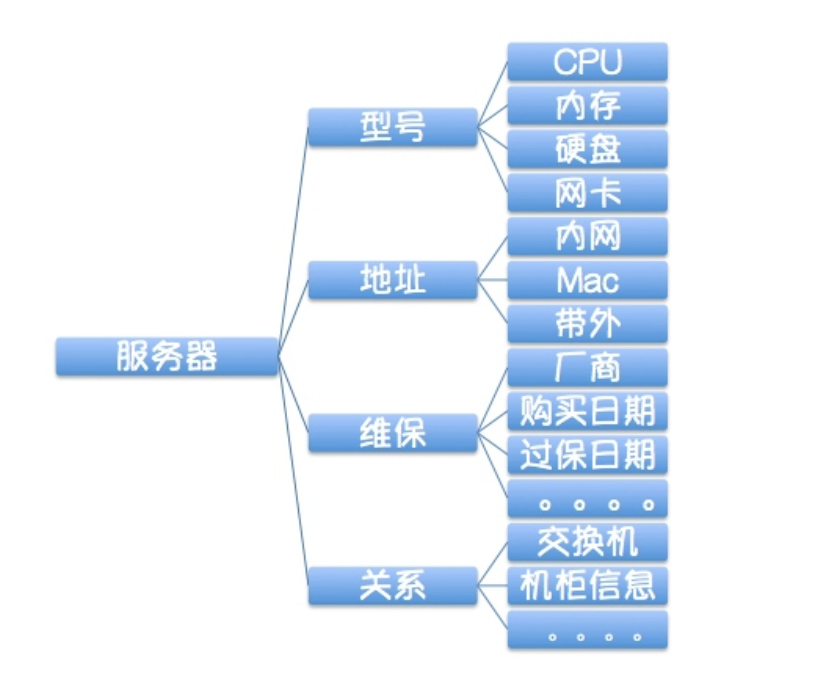
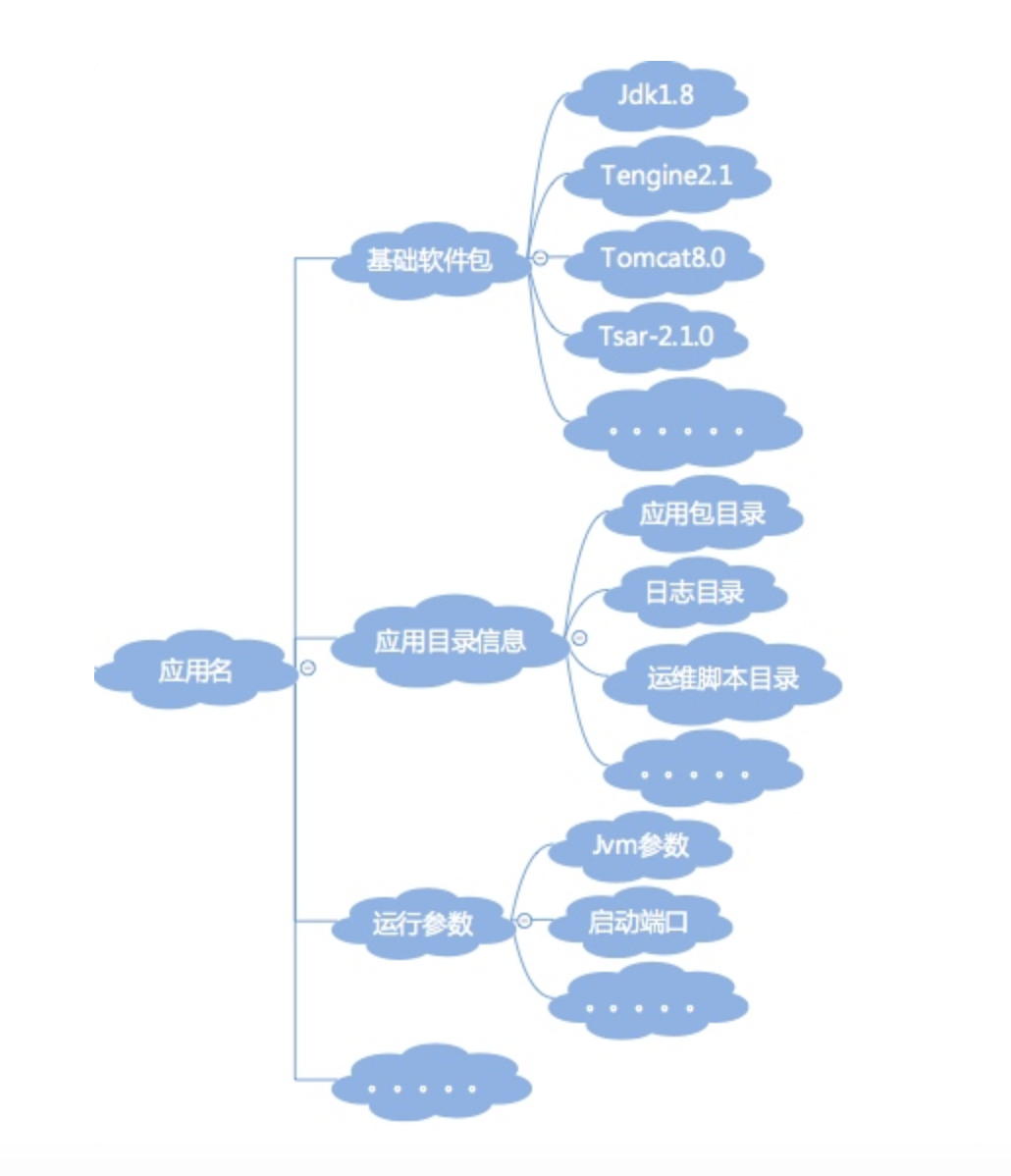
应用层面的标准化
*应用的元数据属性,也就是简单直接地描述一个应用的信息,如应用名、应用 Owner、所属业务、是否核心链路应用以及应用功能说明等,这里的关键是应用名;
*应用代码属性,主要是编程语言及版本(决定了后续的构建方式),GitLab 地址;
*应用部署模式,涉及到基础软件包,如语言包 Java、C++、Go 等;容器如 Tomcat、JBoss 等;
*应用目录信息,如运维脚本目录、日志目录、应用包目录、临时目录等;
*应用运行脚本,如启停脚本、健康监测脚本;
*应用运行时的参数配置,如运行端口、Java 的 JVM 参数 GC 方式、新生代、老生代、永生代的堆内存大小配置等。
常见的分布式基础架构组件
分布式服务化框架,业界开源产品比如 Dubbo、Spring Cloud 这样的框架;
分布式缓存及框架,业界如 Redis、Memcached,框架如 Codis 和 Redis Cluster;
数据库及分布式数据库框架,这两者是密不可分的,数据库如 MySQL、MariaDB 等,中间件如淘宝 TDDL(现在叫 DRDS)、Sharding-JDBC 等。当前非常火热的 TiDB,就直接实现了分布式数据库的功能,不再额外选择中间件框架;
分布式的消息中间件,业界如 Kafka、RabbitMQ、ActiveMQ 以及 RocketMQ 等;
前端接入层部分,如四层负载 LVS,七层负载 Nginx 或 Apache,再比如硬件负载 F5 等。
CMDB 应用配置管理
运维的组织架构
基础运维,包括 IDC 运维、硬件运维、系统运维以及网络运维;
应用运维,主要是业务和基础服务层面的稳定性保障和容量规划等工作;
数据运维,包括数据库、缓存以及大数据的运维;
运维开发,主要是提供效率和稳定性层面的工具开发。
谷歌SRE运维模式解读
SRE 关注的目标不是 Operation(运维),而是 Engineering(工程)
SRE 岗位的职责
书中对 SRE 的职责定义比较明确,负责可用性、时延、性能、效率、变更管理、监控、应急响应和容量管理等相关的工作。如果站在价值呈现的角度,我觉得可以用两个词来总结,就是“效率”和“稳定”
我们先从生命周期的角度,对环境做个简单说明,主要包括:
开发环境,主要是在应用或软件开发过程中或完成后,开发人员对自己实现的代码进行单元测试、联调和基本的业务功能验证;
集成环境,开发人员完成代码开发并自验证通过后,将应用软件发布部署到这个环境,测试人员再确保软件业务功能可用,整个业务流程是可以走通的;
预发环境,在真实的生产数据环境下进行验证,但是不会接入线上流量,这也是上线前比较重要的一个验证环节;
Beta 环境,也就是灰度环境或者叫金丝雀发布模式。为了整个系统的稳定性,对于核心应用,通常会再经历一个 Beta 环境,引入线上万分之一,或千分之一的用户流量到这个环境中;
线上环境,经历了前面几个阶段的业务功能和流程验证,我们就可以放心地进行版本发布了,这个时候就会将应用软件包正式发布到线上 。
环境配置管理解决方案
方案一,多个配置文件,构建时替换。
开发环境 dev_config.properties
预发环境 pre_config.properties
线上环境 online_config.properties
方案二,占位符(PlaceHolder)模板模式。
我们可以看到,这种模式下,配置项的值用变量来替代了,具体的值我们可以设置到另外一个文件中,比如 antx.properits(这个文件后面在 autoconfig 方案中我们还会介绍),这里面保存的才是真正的实际值。
这时我们只需要保留一个 config.properties 文件即可,没必要把值写死到每个不同环境的配置文件中,而是在构建时直接进行值的替换,而不是文件替换。这个事情,Maven 就可以帮我们做,而不再需要自己写脚本或逻辑进行处理。
新书 |《进化:运维技术变革与实践探索》